
On Adaptive Attacks to Adversarial Example Defenses
해당 논문 리뷰는 arxiv에 개제된 ‘On Adaptive Attacks to Adversarial Example Defenses’논문과 논문에 대한 리뷰 영상을 참고하여 작성하였다.
1. Introduction
-
해당 논문은 현재 SOTA 성능을 보이고 있는 Adversarial Defense 방법이 일부 공격에만 대응할 수 있으며, robustness가 과대평가되고 있다고 주장하고 있다.
-
따라서 해당 논문은 여러 top-tier conference나 저널들에 개제된 논문에서 내세우고 있는 모델들을 살펴보며 이것들이 과연 어떠한 공통점을 가지고 있는지, 어떠한 문제를 가지고 있는지 분석한다.
-
분석한 내용을 바탕으로 Adversarial Defense를 위한 논문을 작성할 때 어떠한 것이 고려되야 하는지에 대한 가이드라인을 제시한다.
2. Backgrounds
2.1 Whitebox Attacks
White box attack이란 adversary가 defense 모델에 완전히 접근할 수 있는 공격을 지칭한다. 기본적으로 다음과 같은 공식으로 나타낼 수 있다.
$\lVert x-x’ \rVert_p \le \epsilon$
위 공식은 $p$-norm 만큼의 peturbation을 이미지 데이터 $x$에 가하여 오분류를 일으키게 하는 것으로 해석할 수 있다.
또 다른 White-box 계열의 attack 중에 adaptive attack이 있다. 해당 방법은 adversary가 defense 모델에 완전히 접근하여 최적화된 공격을 하는 것이다. 이 방법이 더욱 주목 받아야 하는 이유는, adversarial attack을 다룬 대다수의 논문은 기존의 공격 방법을 막을 수 있는 방법만 제시하였지, 새로운 adaptive attack 공격에 대한 방어 방법은 제시하지 못했기 때문이다. 다행이 adaptive attack에 대한 방어 방법을 제시하고 있는 논문은 점차 그 수가 많아지고 있는 추세이며, 그 중요성 또한 점점 주목받고 있다.
3. Why were all defenses still broken
앞서 말했듯이 논문에서 제시하고 있는 방어 방법이 불안정한 이유는 adaptive attack에 효과적으로 대응하지 못해서라고 요약할 수 있다.
3. Observations
해당 섹션은 현재 제일 좋은 성능을 보이고 있는 13가지 adversarial attack 방법에 대해 분석을 하여 defense system이 공통적으로 가지고 있는 문제점을 제시한다.
3.1 Don’t intentionally obfuscate gradients
몇몇 defense system은 gradient를 난독화(obfuscate)하거나 숨김으로써 gradient-based attack을 방어한다. 그러나 이러한 방법은 gradient-free attack에 매우 취약하므로 추구해야할 방향이 아니다.
3.2 Don’t bilndly re-use prior attacks
대부분의 defense system은 다음의 두가지 공격을 막는 것을 목표로 한다.
- 이전의 defense system이 막을 수 없던 공격.
- 모든 defense system에 적용할 수 있는 universal attack. 이에 대한 대표적인 예시로 BPDA와 EOT가 있다.
그러나 이러한 defense system은 앞서 말했듯이 adaptive attack에 매우 취약하며, 위 두가지 공격방법에 대한 방어보다 adaptive attack에 대해 막을 수 있는 방법이 먼저 제시되야 할 것이다.
3.3 Don’t complicate the attack
많은 defense system들은 점점 복잡해지고 있다. defense system의 구조를 아래 figure과 같이 나타낼 수 있을 것이다.
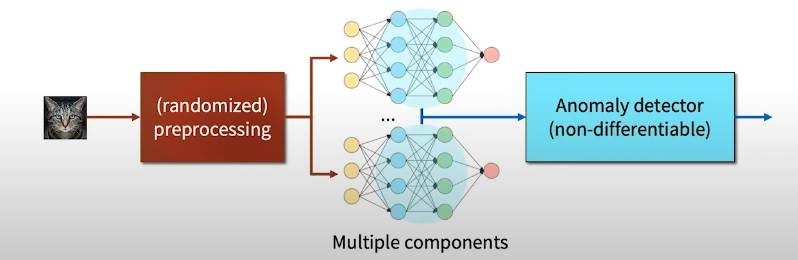
즉, 이미지가 복잡한 전처리 과정을 거치고 feature embedding이 나오게 되고, 이것은 다시 MLP를 거친 후에 non-differentiable한 anomaly detector가 perturbed된 이미지인지 아닌지 여부를 판별한다. 이 방법은 adversary가 anomaly detector 자체를 미분하려고 할 때 효과적으로 막을 수 있는 방법이나, 만약 아래와 같은 예시처럼 이미지를 다른 class로 속이게 하는 perturbation을 추가하는 공격은 막을 수 없게 된다.
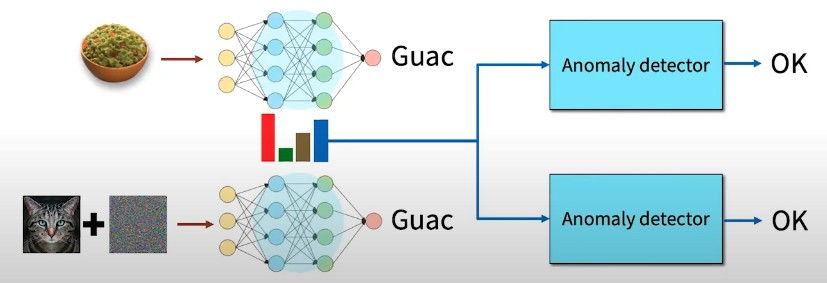
4. Meta point
이 논문에서는 다음과 같은 메세지를 강조하고 있다.
‘Don’t convince reviewers, convince yourself’
위 메세지를 통해 전달하고 싶은 내용은 다음과 같다.
- Adversarial attack 방법을 체크 리스트로 만들고 이를 하나씩 체크해 가며 본 논문에서 제시하는 defense system이 이러한 공격 방법을 막을 수 있다고 말하는 것은 부적절하다.
- Adaptive attack에 대한 방어 성능도 반드시 제시해야 한다.
5. The problem
만약 자기가 제안한 defense system이 제안한 시점에 모든 공격에도 다 막을 수 있는 성능을 보였으나 시간이 지나고 해당 defense system을 뚫을 수 있는 공격이 개발되었다고 해보자. 그렇다면 어떻게 해야할까?
- 해당 논문에서 제안한 아이디어를 바탕으로 한 다른 defense system이 나올 수 있으므로 어떠한 공격에 취약한지 알려주는 내용을 늦게라도 추가해야 한다.
- 만약 다른 논문에서 제안하고 있는 defense system이 특정 공격에 무너지는 결과를 보이면 해당 논문의 저자를 연락해서 이러한 사실을 알려야 한다.
6. Conclusion
해당 논문에서는 다음과 같은 3가지 사항을 강조한다.
- 일부 adversarial attack에 대한 defense system을 제안하는 것은 올바르지 않다. Adaptive attack을 포함한 모든 공격을 가했음에도 불구하고 robust한 defense system이라는 것을 여러 실험을 통해 증명해 낼 수 있어야 한다.
- 최대한 쉬운 공격 방법부터 가해야 한다.
- 만약 defense system이 특정 공격에 의해 뚫리면 뚫린 사실을 인정하고 더 발전된 defense system을 개발하는 것을 목표로 연구를 해야한다.
Comments