
Assignment 1
Assignment 1은 파이썬 코드를 직접 작성하여 이미지 분류 모델을 직접 만드는 내용이다. 사용하는 모델로는 KNN, SVM, two-layer-net(deep learning network with one hidden layer) 이 있다. 이 모델들에 대해서는 예전에 배운 기억이 있으나 복습할 겸 다시 정리해볼 필요가 있다고 생각한다.
K-Nearest Neighbor
KNN은 K-Nearest Neighbor의 약자이다. 이를 한글로 직역하면 K-최근접 이웃이고, 이 이름을 통해 알 수 있듯이 새로운 데이터 포인트에 대해 예측할 때는 훈련 데이터셋에서 가장 가까운 데이터 포인트, 즉 ‘최근접 이웃’을 찾는다. 다음과 같이 두개의 클래스, 0과 1로 구분된 데이터 포인트들이 있다고 하자.
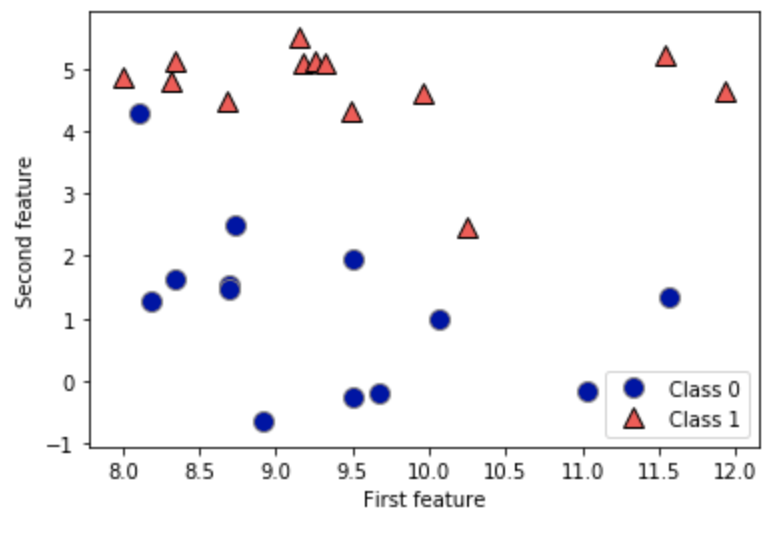
KNN에서 설정할 수 있는 대표적인 인수로는 n_neighbor, 즉 분류하고 싶은 데이터 포인트로 부터 가까운 n개의 데이터 포인트를 설정할 수 있다.
만약 n_neighbor을 1로 설정하면 다음과 같이 데이터 포인트로부터 가까운 점 한 개만을 찾고 그 점의 클래스로 데이터 포인트를 분류한다.
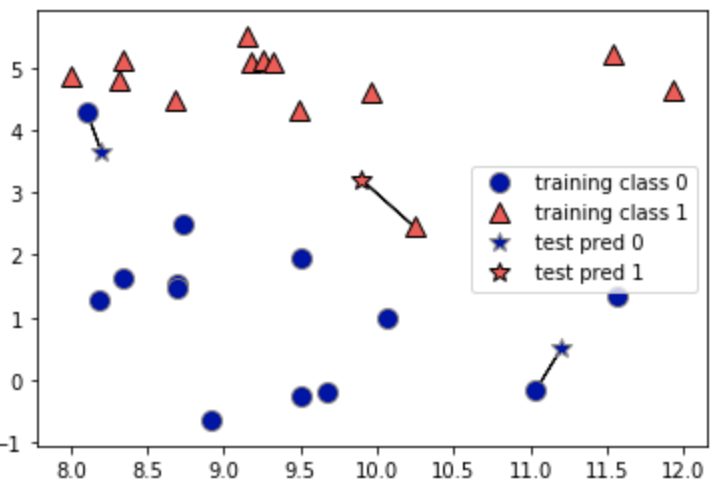
n_neighbor을 3으로 설정하면 다음과 같이 데이터 포인트로부터 가까운 점 3개를 찾고 점들 중 다수인 클래스로 분류한다.
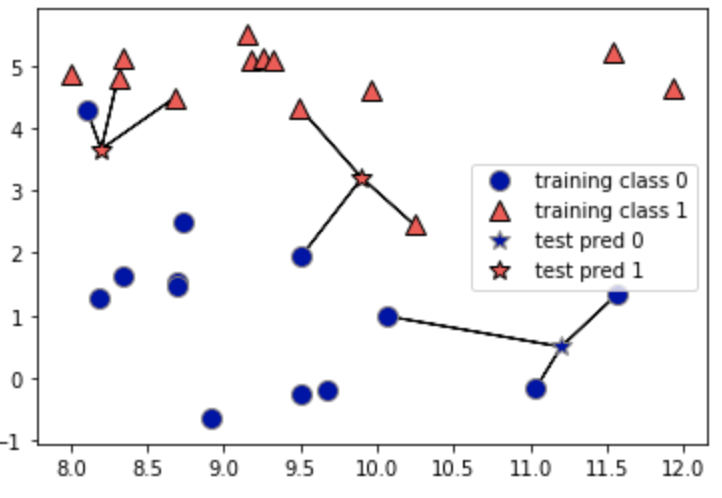
위 사진을 통해 n_neighbor를 낮게 설정할수록 overfitting, 높게 설정할수록 underfitting 이 되는 것을 확인할 수 있다.
Pros and Cons of KNN
Pros:
- 이해하기 매우 쉬운 모델이다.
- 매개변수를 많이 조정하지 않아도 자주 좋은 성능을 발휘한다.
Cons:
- 훈련 세트가 매우 크면 예측이 느려진다. 따라서 훈련 전에 데이터를 전처리 하는 과정이 매우 중요하다.
- (수백 개 이상의) 많은 특성을 가진 데이터셋에는 잘 동작하지 않으며, 특성 값 대부분이 0인 데이터셋과는 특히 잘 작동하지 않는다.
Comments