
Lecture 12: Visualizing and Understanding CNN
지금까지 CNN의 작동 원리와 CNN을 통해 컴퓨터가 이미지를 읽고 처리하는 과정을 알아보았다. 그렇다면 CNN의 각 층에서 이미지가 어떠한 형식으로 나타나게 될까? CNN의 작동 과정을 좀 더 직관적으로 알기 위해 시각화 하는 방법에 대해 이 단원은 다루고 있다.
What’s going on inside convolutional layer?
각 레이어에서 필터가 이미지를 훑고 지나가 지나간 이미지에 대한 정보를 저장하게 된다. 이렇게 저장한 이미지를 시각화하면 각 필터가 이미지에서 어떠한 정보를 찾으려고 하는지에 대해 알 수 있다. 다음은 각 CNN 모델에서 레이어별로 필터가 어떠한 정보를 찾아내었는지에 대해 나타난 사진이다.
First Layer: Visualize Filters
먼저 첫번째 레이어가 어떠한 정보를 찾아내었는지 확인해보자.

여기서 AlexNet의 64x3x11x11은 11x11 크기의 64개의 필터가 R,G,B 각각의 값 별로 이미지 픽셀에 가중치 값을 곱한 결과이다. 위의 사진에서 알 수 있듯이 첫번째 레이어는 대체적으로 이미지의 low-level 특징들, 즉 이미지에 나타난 점, 선, 패턴 등에 대해서 찾으려고 한다.
Last Layer
마지막 레이어는 fully connected layer 이므로 4096 차원을 가지고 있는 벡터 데이터이다. 이 레이어는 주로 이미지의 문맥적인(semantic) 특징들을 찾는다. 최근접 이웃(Nearest Neighbor) 방법을 이용해 테스트 이미지와 특징이 비슷한 이미지를 찾으면 사진이 알맞게 분류되는 것을 확인할 수 있다.

Last Layer: Dimensionality reduction
4096 차원이나 되는 마지막 레이어를 한번에 시각화하기란 거의 불가능한 작업이다. 따라서 이를 한번에 시각화하기 위해 차원을 축소해야 할 필요성이 있다. 이를 하기위한 간단한 알고리즘으로 PCA(Principle Component Analysis)가 있지만 여기서는 좀더 복잡한 t-SNE 알고리즘을 사용하였다.
다음은 imageNET의 이미지들에 t-SNE를 적용하여 시각화하는 과정이다.
- 이미지들을 CNN을 통해 훈련시켜 마지막 레이어에 저장된 4096 차원의 벡터를 추출한다.
- t-SNE를 통해 2차원으로 데이터를 축소한 후 2차원 좌표에 위치시켜 나타낸다.
- 비슷한 특징을 가진 이미지끼리 군집을 형성하게 된다.

Maximally Activating Patches
특정 레이어가 어떠한 정보를 찾는지 알기 위해서 Maximally Activating Patches 방법을 이용한다. 이 방법은 특정 레이어의 특정 채널을 선택한 후 여러 이미지를 통과시켜 학습하는 값들은 저장한다. 그리고 최대로 활성화하는데 사용되는 값을 선택해 이를 시각화한다. 이 방법을 통해 시각화한 결과를 보면 특정 레이어의 특정 채널은 이미지에서 비슷한 정보를 찾는다는 것을 알 수 있다.

Saliency Maps
이미지의 특정 부분을 가린 후에 CNN을 통해 훈련시키고 이를 분류한 결과가 가리지 않은 이미지를 훈련시킨 결과와 큰 차이를 보인다면 가린 부분이 분류하는데 굉장히 중요한 역할을 차지한다는 것을 알 수 있다. 이러한 과정을 이미지의 모든 부분에 적용시켜 이미지의 분류를 위해 중요한 부분을 찾은 결과를 Saliency Maps 라고 한다.

왼쪽 이미지에서 CNN은 이미지 분류의 중요한 역할을 차지하는 부분, 즉 강아지의 모습을 제대로 찾아내었다. 오른쪽 이미지 또한 과일을 제대로 찾아내었다.
Intermediate features via guided backprop
guided backprop 이란 일반 역전파 과정에서 양수 미분 값을 통해서만 역전파하는 것이다. 이렇게 하면 일반 역전파를 하는 것보다 더 깨끗한 이미지를 얻을 수 있다는 장점이 있다.
그리고 이 guided backprop을 특정 레이어의 특정 뉴런에 적용하면 그 뉴런에 대한 이미지 픽셀의 미분 값을 얻을 수 있다. 그에 대한 결과로 다음과 같이 각 이미지당 뉴런이 찾는 특징들에 대해 알 수 있다.

Gradient Ascent
gradient descent가 손실 값을 최소화하기 위해 각 뉴런에 연결된 가중치 값을 변경하였다면 gradient ascent는 각 클래스별 점수를 최대로 하기 위해 가중치 값은 그대로 유지하고 이미지의 픽셀 값만 변화 시킨다. gradient ascent를 공식으로 나타내면 다음과 같다.
$I^{*}=argmax_If(I)+R(I)$
여기서 $f(I)$ 는 뉴런에 저장된 값, $R(I)$는 Natural image regularizer이다. Natural image regularizer은 이미지 픽셀 값을 변화할 때 최대한 자연스러운 이미지가 만들어지도록 정규화해주는 변수이다. CNN을 통해 gradient ascent가 이루어지는 과정은 다음과 같다.
- 이미지의 모든 픽셀 값에 0을 부여한다.
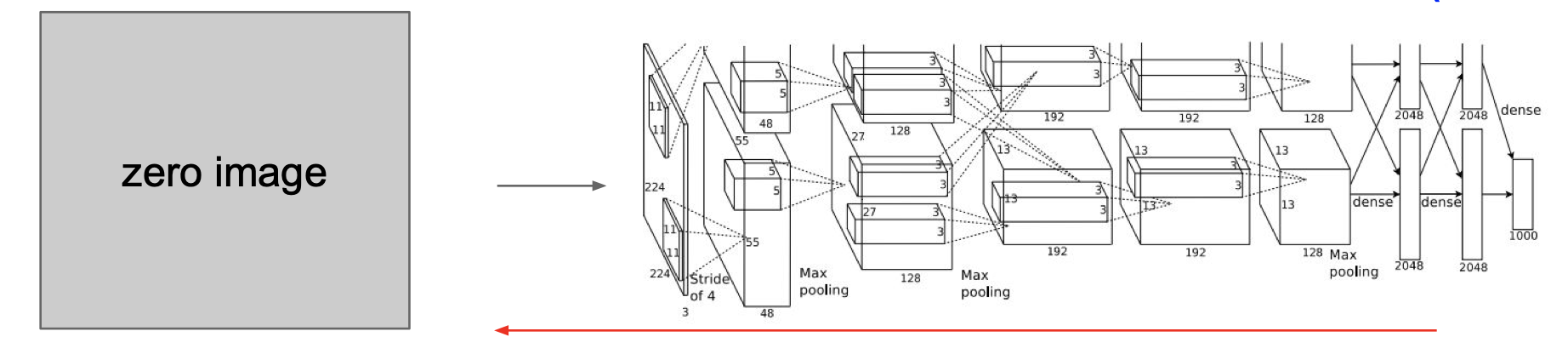
다음 과정을 반복한다:
- CNN으로 클래스별 점수를 계산한다.
- 역전파를 하며 이미지의 각 픽셀에 대한 뉴런의 미분 값을 계산한다.
- 픽셀 값에 작은 변화를 준다.
다음은 gradient ascent를 통해 이미지를 변경한 모습이다.

약간은 가시성이 떨어지는 배경 속에 레이블에 해당하는 모습이 희미하게 나타나는 것을 확인할 수 있다.
Utilzing Gradent Ascent
지금까지 배운 내용을 활용하여 재밌으면서 기발한 활동들을 해볼 수 있다.
DeepDream
Gradient Ascent가 각 클래스별 점수를 최대로 만들기 위해 이미지 픽셀에 변화를 주었다면, DeepDream은 레이어의 활성화 함수를 통해 계산한 값을 최대로 만들기 위해 이미지 픽셀에 변화를 준다. 즉, DeepDream은 다음과 같은 과정을 통해 작동한다.
- 이미지와 CNN의 한 레이어를 선택한다.
- 선택한 레이어의 활성화 함수를 통해 계산한 값에 대한 미분 값을 구한다.
- 계산한 미분 값을 통해 역전파를 하여 이미지의 픽셀 값을 변화시킨다.
다음과 같은 하늘 이미지에 DeepDream을 적용한다고 하자.

다음은 CNN에서 높은 레이어를 선택한 후 DeepDream을 적용한 모습이다.

다음은 CNN에서 낮은 레이어를 선택한 후 DeepDream을 적용한 모습이다.

위 두 사진에서 알 수 있듯이 높은 레이어를 선택하면 높은 레벨의 이미지들(개, 고양이, 물고기 등)이 하늘에 나타나지만 낮은 레이어를 선택하면 낮은 레벨의 이미지들(모서리, 알 수 없는 이상한 패턴들 등)이 하늘에 나타나는 것을 알 수 있다.
Feature Inversion
Feature Inversion은 학습한 CNN모델의 특정 레이어를 통해 이미지를 만드는 방법이다. Gradient Ascent와 같은 개념을 공유하나 차이점이라면 Gradient Ascent가 각 클래스별 점수를 최대로 만들기 위해 픽셀 값을 조정하였다면 Feature Inversion은 원래 이미지와 다시 만든 이미지의 차이를 줄이기 위해 픽셀 값을 조정한다. 다음은 각 레이어별로 Feature Inversion을 적용한 모습이다.

높은 레이어를 선택할수록 높은 레벨의 특징들이 선택된다. 즉, 낮은 레이어일수록 낮은 레벨의 특징들(색, 물체의 테두리, 전체적인 윤곽등)을 학습하고 높은 레이어일수록 높은 레벨의 특징들(주로 semantic 하다.)을 학습한다.
Texture Synthesis
Texture synthesis란 다음과 같이 작은 입력 이미지를 이어 붙여서 큰 이미지를 만드는 과정이다.
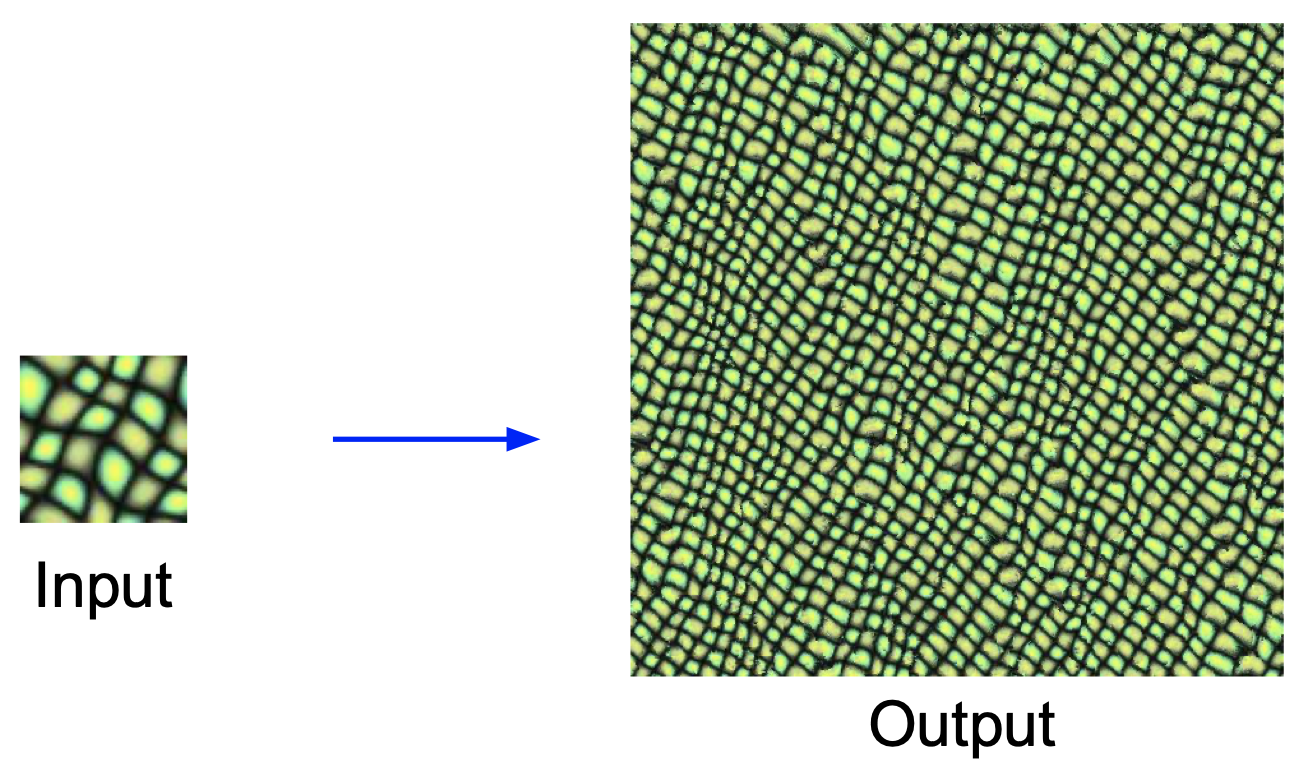
Texture synthesis를 하기 위한 간단한 알고리즘으로 최근접 이웃(Nearest Neighbor)이 있지만 이 강의에서는 Neural Texture Synthesis 알고리즘을 이용하였다. 이 알고리즘의 원리는 다음과 같다.
- CNN의 각 레이어에는 CxHxW 크기를 가진 특징 행렬이 있는데, 이 행렬은 C차원의 특징 벡터가 HxW 만큼 있는 것으로 이해할 수 있다.
- HxW 상의 C 특징 벡터 2개를 선택한 후 이 둘의 외적 값을 구한다.
- 과정2를 HxW상의 모든 특징 벡터에 적용한 후 계산된 값의 평균 값을 구한다.
- 평균 값의 결과로 CxC gram matrix가 나타나는데, 이 행렬은 이미지의 텍스쳐에 대한 정보가 담겨 있다.
- 2~4의 과정을 모든 레이어에 대해 실행한다.
- 이렇게 gram matrix가 포함된 CNN을 새로운 이미지(노이즈가 있는 것이 좋다)에 적용하여 gradient ascent를 통해 CNN에 저장된 텍스쳐대로 이미지를 재구성할 수 있다.
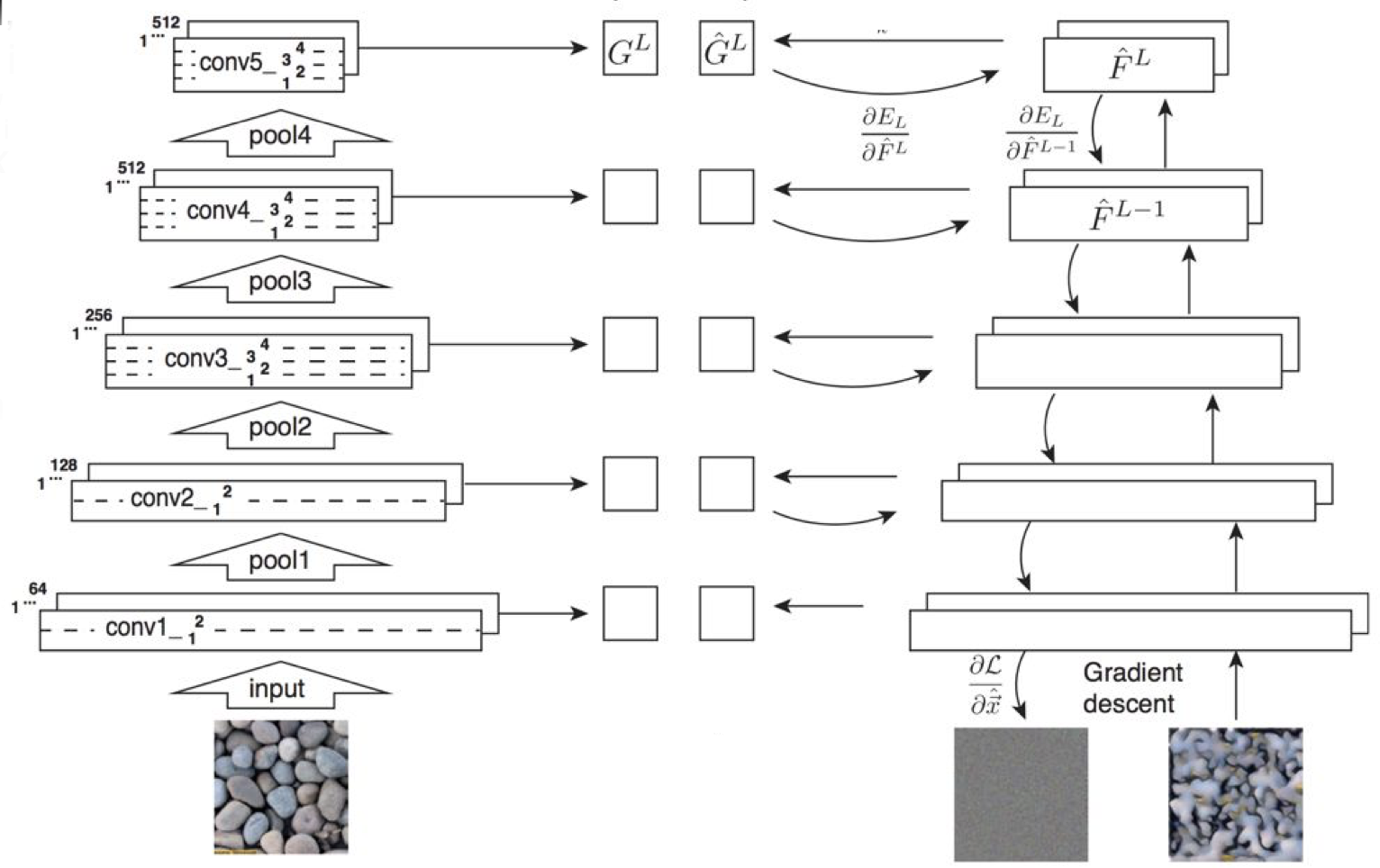
다음은 Texture synthesis를 이용하여 이미지를 재구성한 결과이다.

Natural Style Transfer
Natural Style Transfer란 앞서 배운 feature inversion과 texture synthesis을 동시에 적용하여 이미지의 스타일을 바꾸는 과정이다. 여기서 스타일을 바꾸고 싶은 이미지를 content image, 변경하고 싶은 스타일이 적용된 이미지를 style image 라고 한다. Natural Style Transfer 이 일어나는 원리는 상당히 간단하다.
- style image에 texture synthesis를 적용하여 CNN에 텍스쳐에 대한 정보를 추가한다.
- content image을 텍스쳐에 대한 정보가 추가된 CNN에 적용하여 feature inversion을 통해 노이즈가 있는 이미지(output image)를 새로운 스타일이 적용된 content image로 재구성한다.
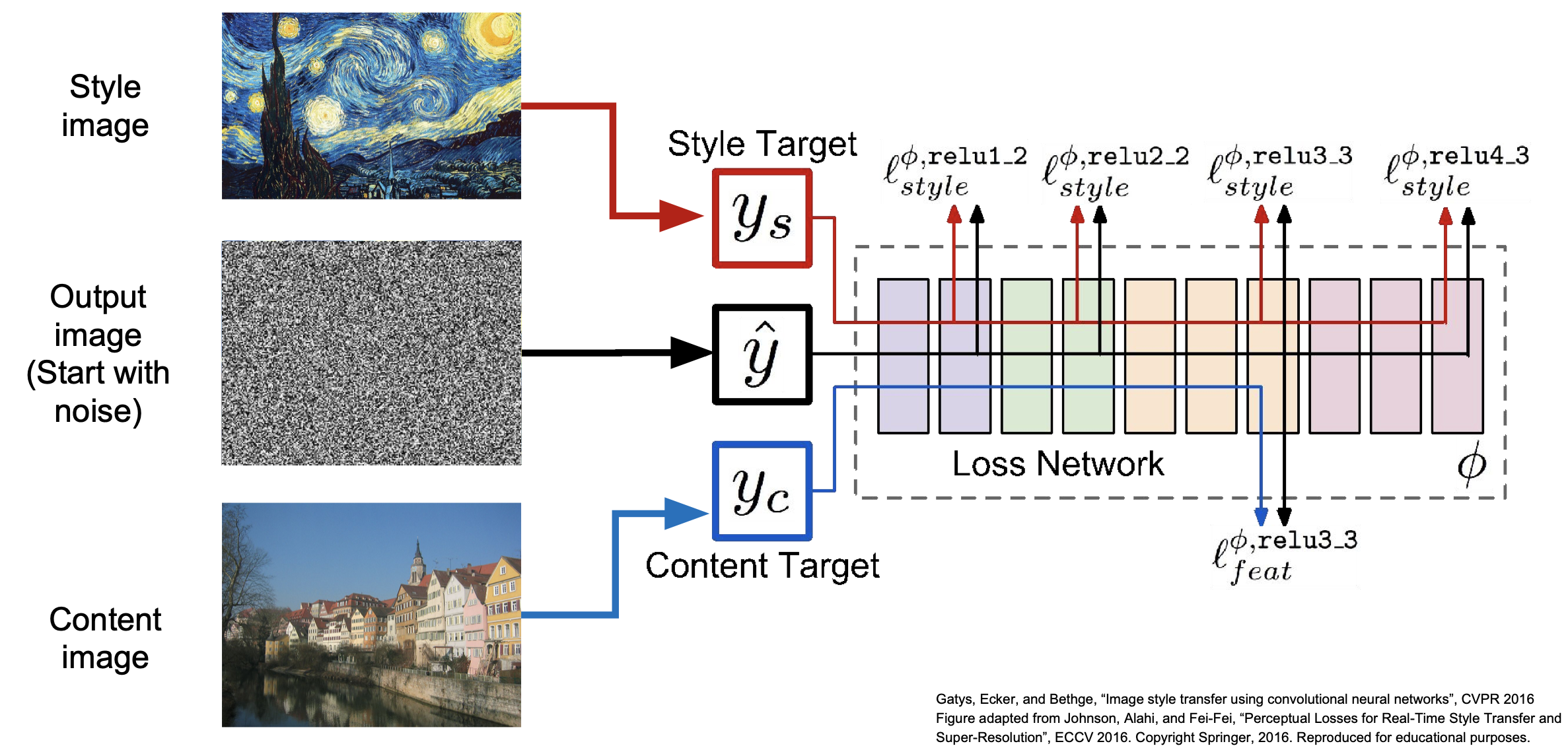
다음과 같이 Natural Style Transfer을 통해 같은 이미지를 다양한 스타일로 변화시킬 수 있다.

여기서 content image와 style image의 가중치 값을 변화시키며 다른 느낌의 이미지를 재구성해 나갈 수 있다.

Fast Style Transfer
Natural Style Transfer 의 단점은 순전파와 역전파가 지나치게 많이 일어나 처리과정이 매우 느리다는 것이다. 이때 content와 style 이미지를 먼저 학습시켜 CNN모델을 만든 후 다른 content 이미지를 적용하면 한 번의 순전파 과정만 일어나기 때문에 매우 빠른 속도로 스타일을 변경할 수 있다. 다음은 이러한 과정을 적용해 실시간으로 이미지를 재구성해 나가는 모습이다.

Summary
CNN이 작동하는 원리를 알기 위한 방법은 매우 다양하다.
- 활성화 값을 통한 방법: 최근접 이웃, 차원 축소, Maximally Activating Patches,
- 미분을 통한 방법: saliency maps, feature inversion
- 이를 활용한 방법: DeepDream, Style Transfer
Comments