
Lecture 2: Image Classification pipeline
원래는 Lecture 3를 정리하기 전에 Lecture 2를 정리했어야 했는데 밀린 Lecture을 듣다가 이제서야 정리를 한다.
Challenges of Computer vision
다음과 같은 고양이 사진을 컴퓨터가 알맞는 레이블로 분류해야 한다고 해보자.

이미지를 분류하는데는 다음과 같은 난관이 존재한다.
- Viewpoint variation
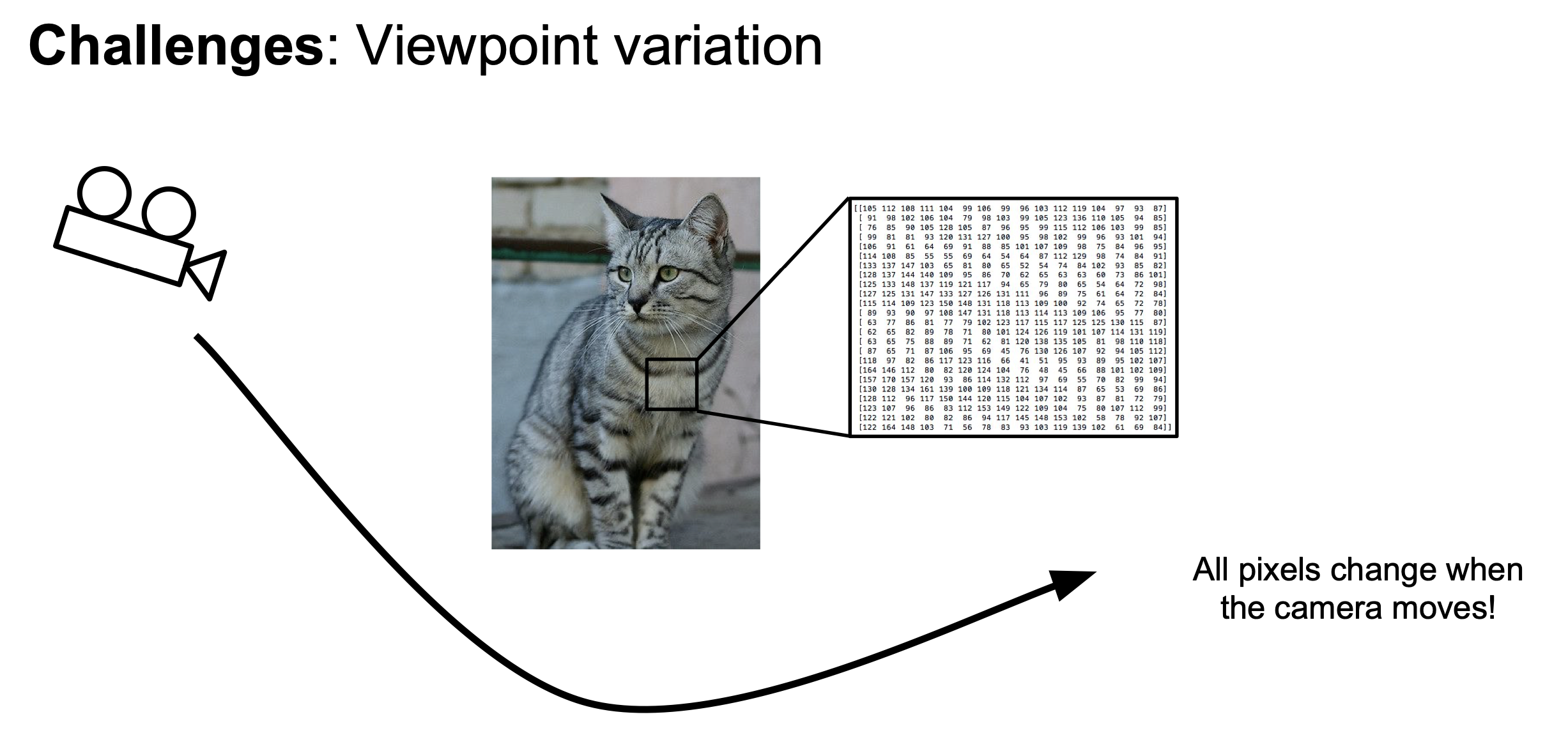
고양이를 보는 카메라의 시점이 달라지면 고양이를 못알아볼 가능성이 생긴다.
- Deformation

고양이가 위 사진처럼 드러 눕거나 훈련한 사진과는 다른 포즈를 취하면 고양이로 분류를 하지 못할 가능성이 생긴다.
- illumination

고양이를 비추는 빛의 양이 변하면 못알아볼 가능성이 생긴다.
- Occlusion

위 사진처럼 고양이가 물체에 가려져 일부만 노출된 경우 못알아볼 가능성이 생긴다.
- 그 밖에 고양이의 뒷배경이 바뀌는 background clutter 또는 고양이가 여러 마리가 추가되는 경우인 intraclass variation 와 같은 경우에도 분류에 어려움이 있을 수 있다.
Classifiers
기계가 이미지를 분류하는 방법은 다음과 같은 과정으로 나타낼 수 있다.
- 방대한 양의 이미지와 레이블 데이터를 수집한다.
- 머신러닝을 이용해 분류기를 훈련 시킨다.
- 새로운 이미지에 분류기를 적용시켜 제대로 작동하는지 테스트 해본다.
이제부터 분류기를 훈련시키는데 사용되는 대표적인 알고리즘 두 개에 대해서 설명하도록 하겠다.
Nearest Neighbor
최근접 이웃 (Nearest Neighbor) 은 단순하게 테스트 이미지 와 훈련 이미지 의 대응되는 각 픽셀 값의 차이가 최소가 되게 만든다. 이 방법에는 다음과 같은 2가지 방법이 사용된다.
- L1 distance: 차이의 절댓값의 합이 최소가 되게 만든다.
- 좌표계에 따라 영향을 받는다
- L2 distance: 차이의 제곱의 합이 최소가 되게 만든다.
- 좌표계에 영향을 받지 않고 단순한 점들의 거리에 의해서만 영향을 받는다.
최근접 이웃을 그림으로 다음과 같이 표현할 수 있다.
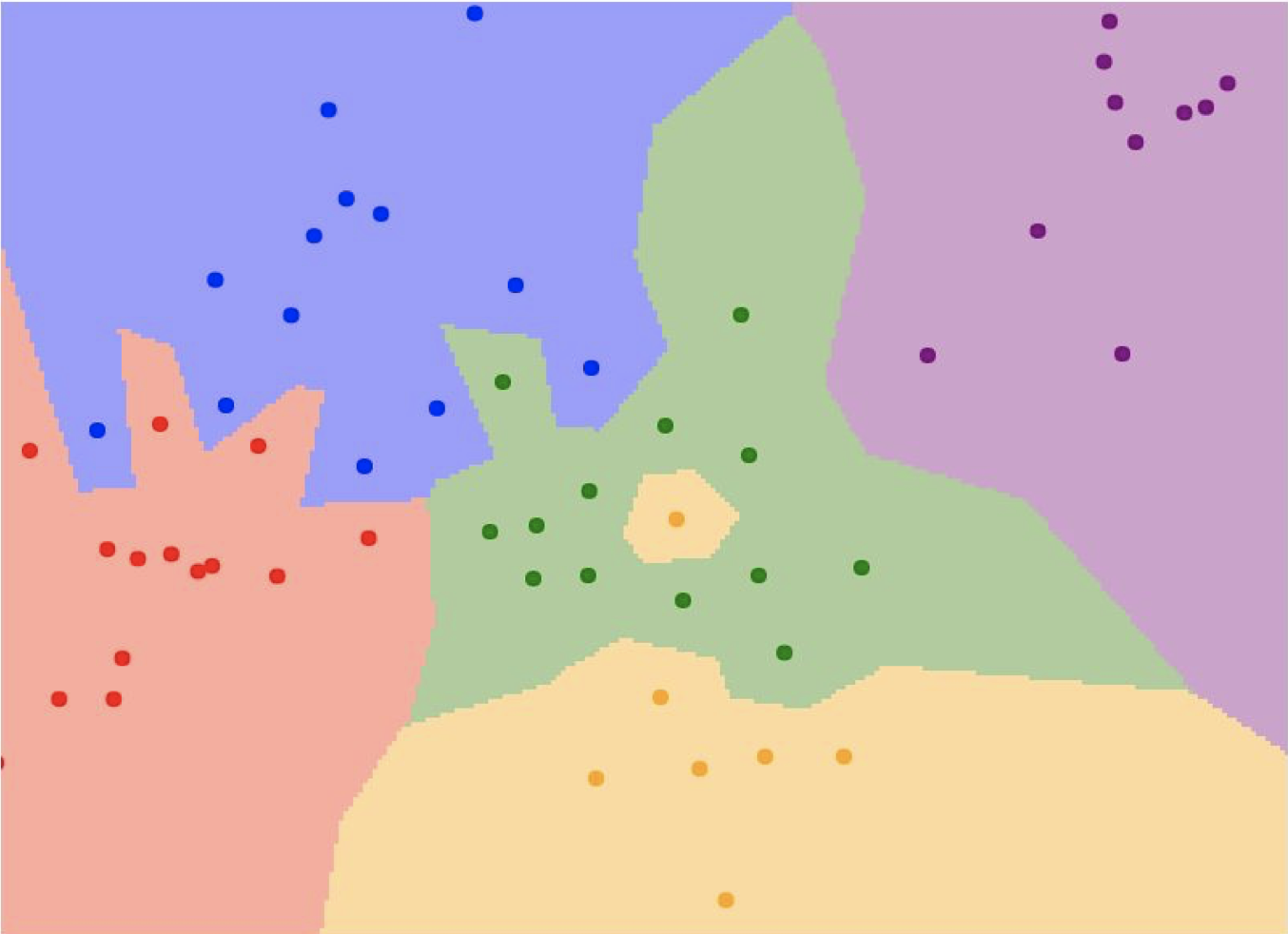
위 사진에서 각각의 점들이 속해있는 영역을 점의 카테고리와 같은 색으로 칠하였다. 그러나 녹색으로 칠해진 영역 한가운데에 노란색 점이 있는 것을 확인 할 수 있을 것이다. 이처럼 점 한 개에 의해 분류를 정상적으로 하지 못하는 경우가 발생하기도 하는데, 이를 과적합 한다고 한다. 따라서 일반 최근접 이웃 방법은 과적합 문제 때문에 잘 사용되지 않고 K-최근접 이웃이 많이 사용된다.
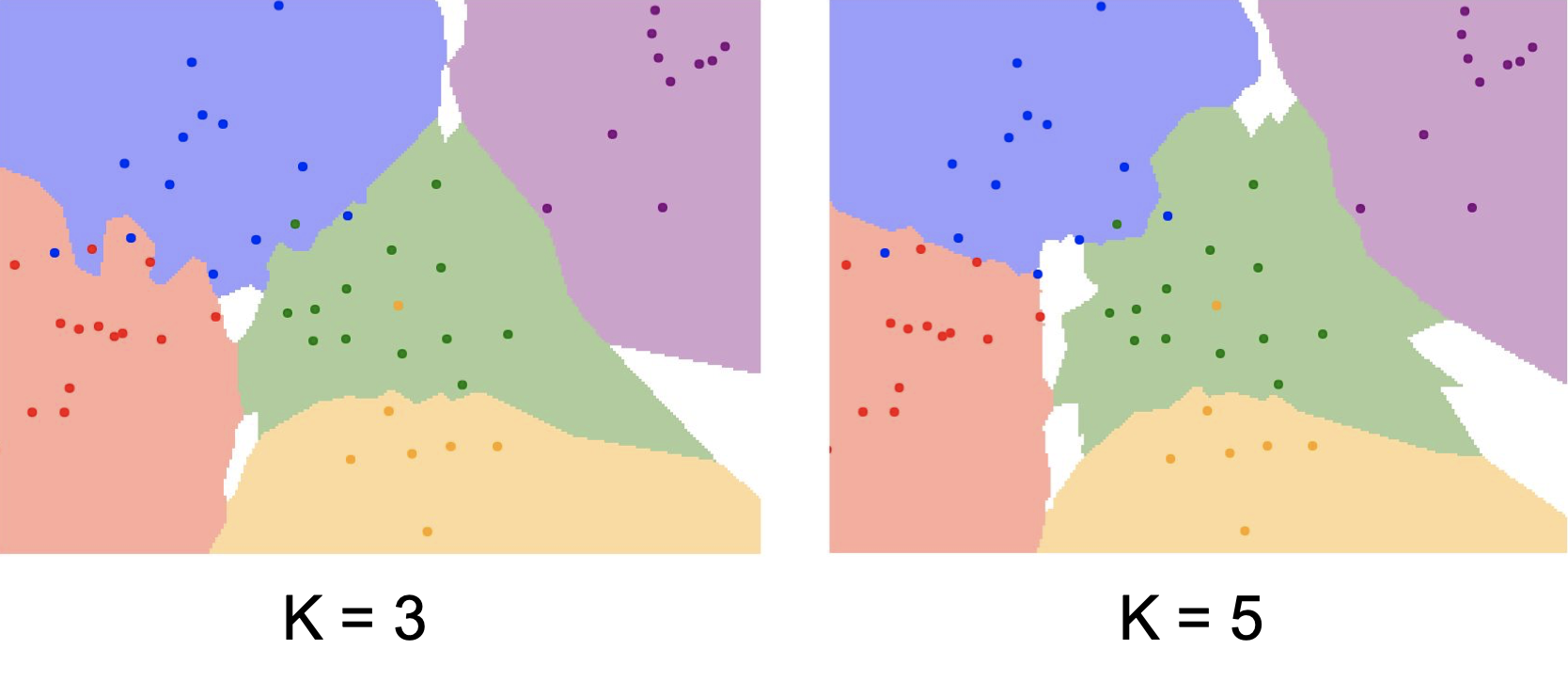
왼쪽 사진은 K=3 으로 설정했을 때, 오른쪽 사진은 K=5 으로 설정했을 때의 모습이다. 기존의 최근접 이웃과는 달리 각 점에서 가장 가까운 K개의 점을 찾아 나타나는 빈도가 더 높은 점의 클래스로 분류한다. 이전보다 훨씬 더 융통성 있게 영역이 설정된 것을 확인할 수 있다.
그러나 정작 이미지 분류에서는 K-최근접 이웃이 잘 사용되지 않는다! 아래 사진을 한번 보자.

위 사진에서 오른쪽 3개 사진은 제일 왼쪽에 있는 사진과의 픽셀의 거리가 모두 동일하다. 그러므로 이러한 거리는 사진에 대한 아무런 정보도 가져다 주지 않는다. 또한 분류기는 훈련 시간에 오래 걸리나 테스트 시간은 짧게 걸리는 가벼운 모델이 되는 것이 제일 이상적이다. 그러나 K-최근접 이웃은 그 반대이다.
Setting Hyperparameters
분류기에서 훈련을 위한 인수(hyperparameters)를 설정하는 것은 매우 중요하다. 인수를 지정하는 방법은 다음과 같이 3가지 방법이 있는데, 훈련 데이터에 대한 분류기의 과적합을 피하기 위해서 3번째 방법인 훈련 데이터, 검증 데이터, 테스트 데이터 로 나누는 것이 좋다.
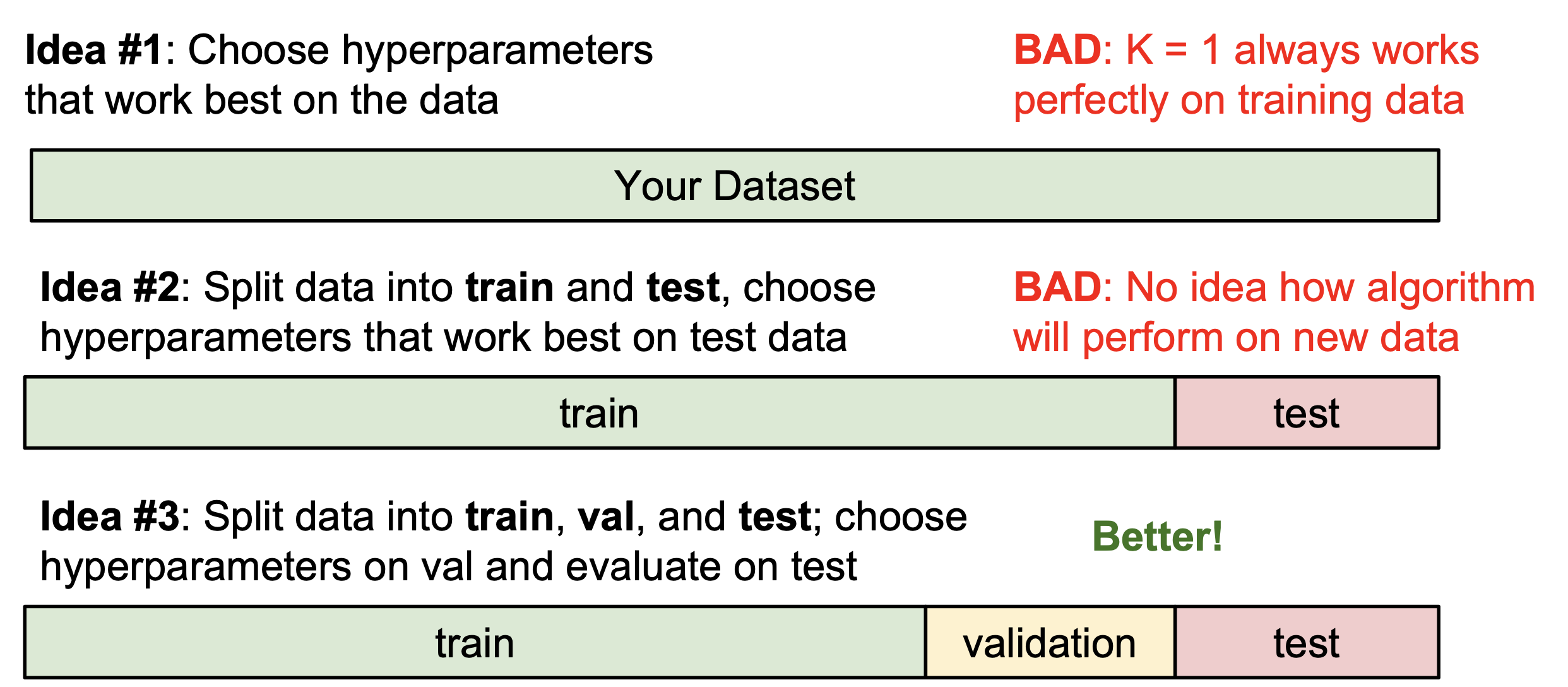
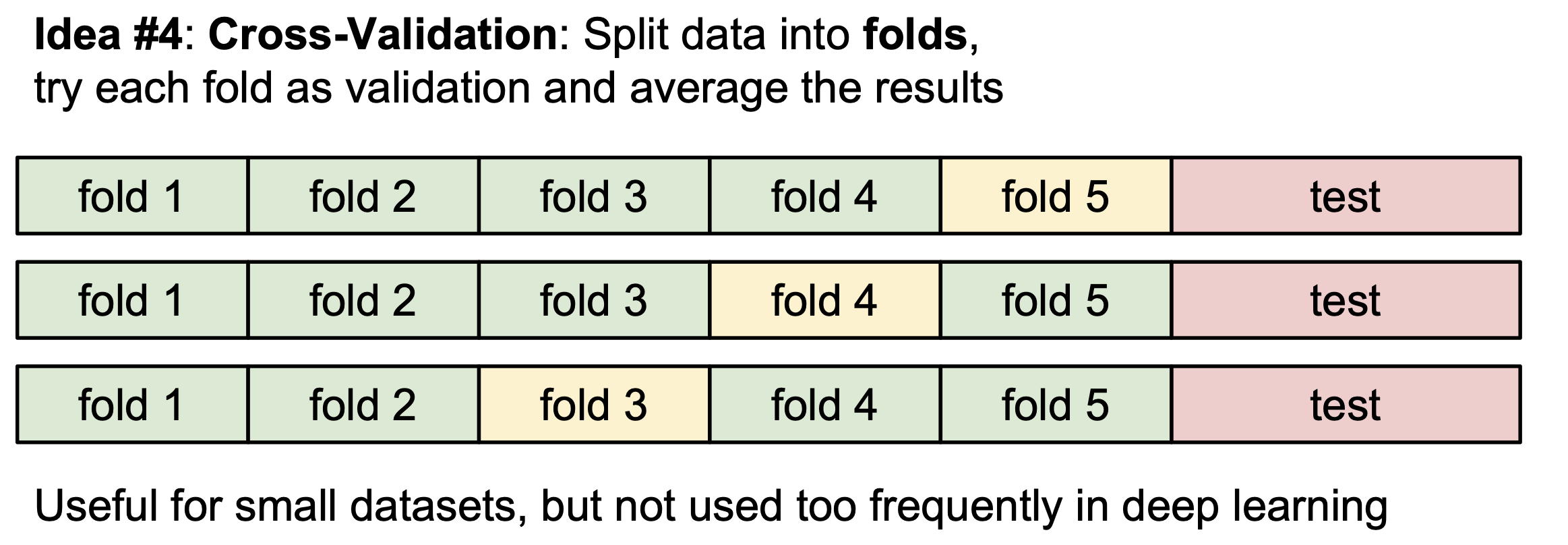
그리고 만약 데이터의 수가 많지 않다면 다음과 같이 데이터를 일정 수만큼의 fold로 나누고 훈련하는 fold와 검증하는 fold를 돌아가면서 설정하는 방법인 K-교차검증 도 추천한다.
Linear Classifier
선형 분류기(Linear Classifier) 은 우리가 곧 중점적으로 배우게 될 Convolution Neural Network 의 근간이 되는 중요한 분류기이다. 선형 분류기는 여러 개의 사진 데이터에서 공통된 특징을 찾아내 이러한 특징에 가중치를 부여하는 방법을 사용한다. 이를 그림으로 표현하면 다음과 같다.
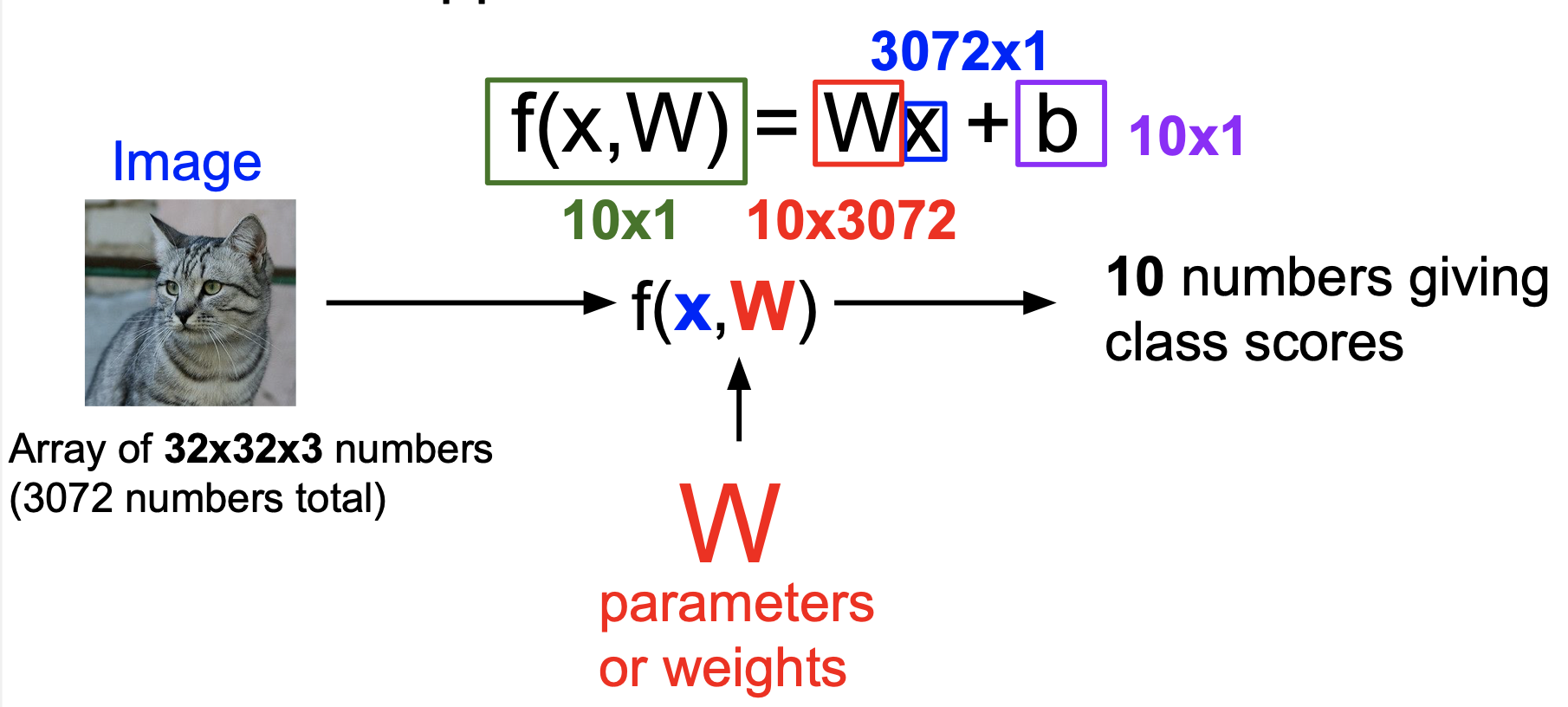
여기서 W는 가중치 행렬, x는 사진 데이터 행렬, b는 bias vector (별로 중요하지는 않다) 이다. 32x32x3의 크기를 가진 사진 데이터가 3072x1의 형태인 1차원의 데이터로 변경된 후 가중치 행렬을 곱하고 bias vector을 더하면 10개의 클래스에 대한 각각의 점수가 나타나게 된다. 그리고 10개의 클래스에 대한 점수 중 가장 높은 점수를 가진 클래스로 분류한다. 위의 사진이 이해하기 어렵다면 4개의 픽셀로 표현된 사진으로 같은 과정을 표현한 아래 사진을 한번 보자.
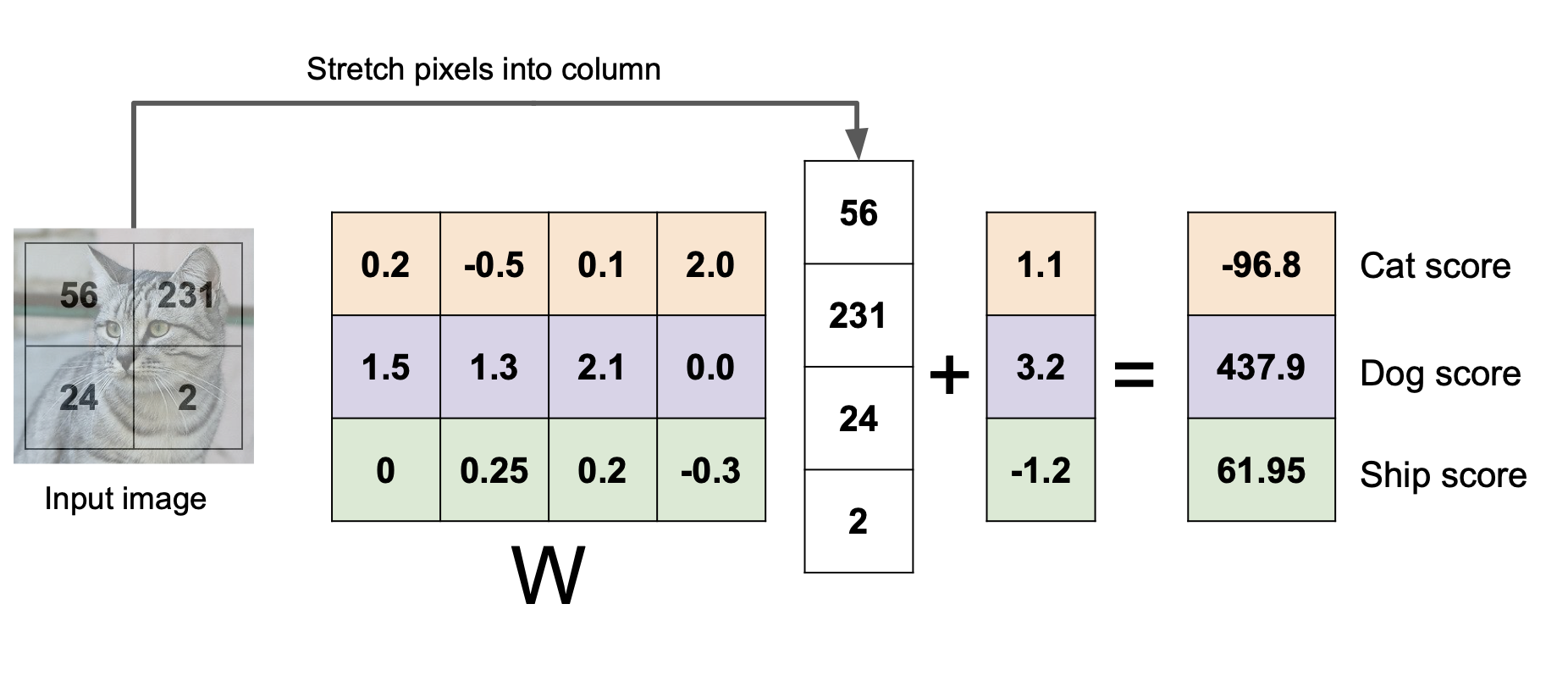
위에서 고양이 클래스의 점수는 -96.8, 개 클래스의 점수는 437.9, 배 클래스 점수는 61.95로 개 클래스의 점수가 가장 높아 해당 사진을 개로 분류했다는 것을 알 수 있다.
다음은 선형 분류기로는 올바르게 분류하기 힘든 경우들이다.
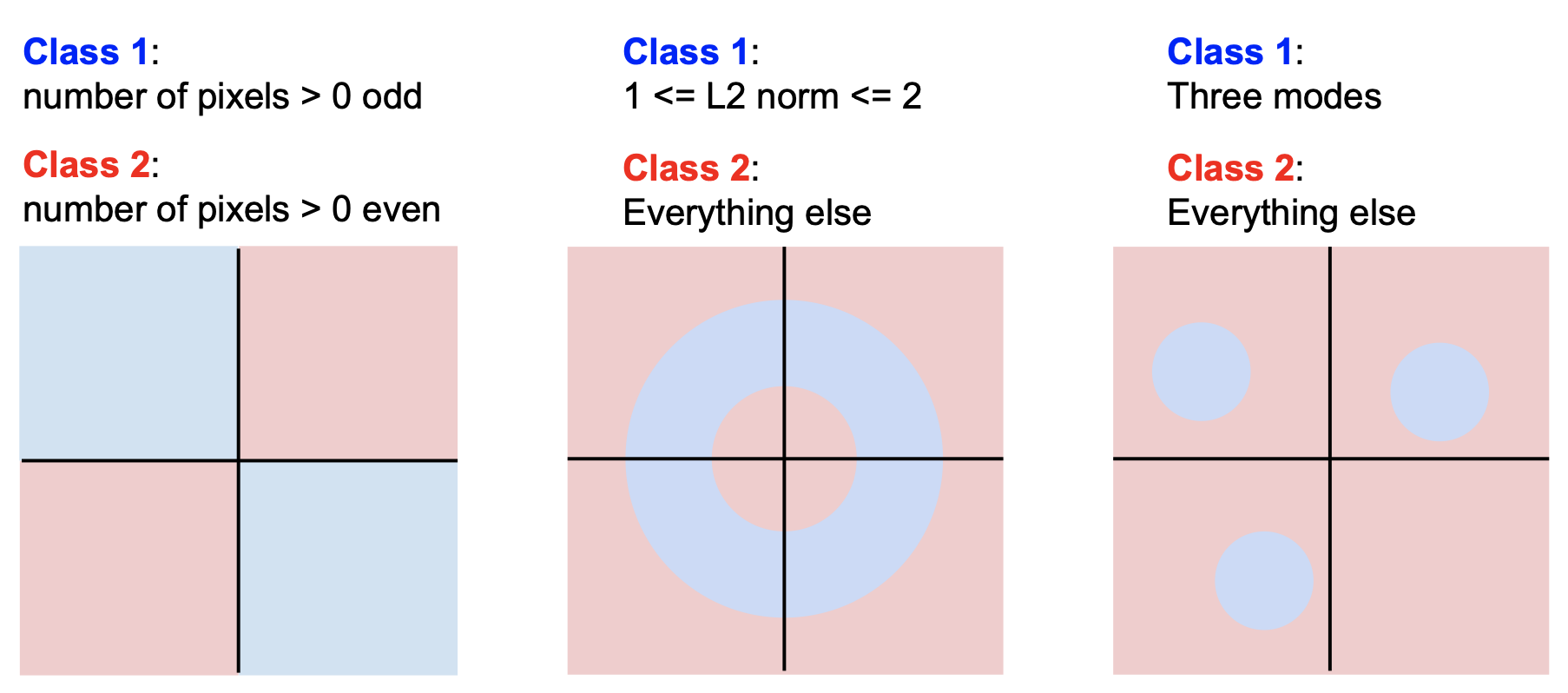
그래프를 통해서만 알 수 있듯이 단 하나의 직선만으로 2개의 클래스를 올바르게 분류하기 힘들다는 것을 알 수 있다.
Comments