
Lecture 6: Training Neural Networks 1
Activation Functions
활성화 함수는 가중치와 입력 데이터를 곱한 값에 정직화 변수를 더한 값을 다음 레이어로 어떠한 값으로 전달할지 지정하는 함수이다. 대표적인 활성화 함수로 Sigmoid, tanh, ReLU, Leaky ReLU, Maxout, ELU 가 있다.
Sigmoid
시그모이드 함수의 모습은 다음과 같다.
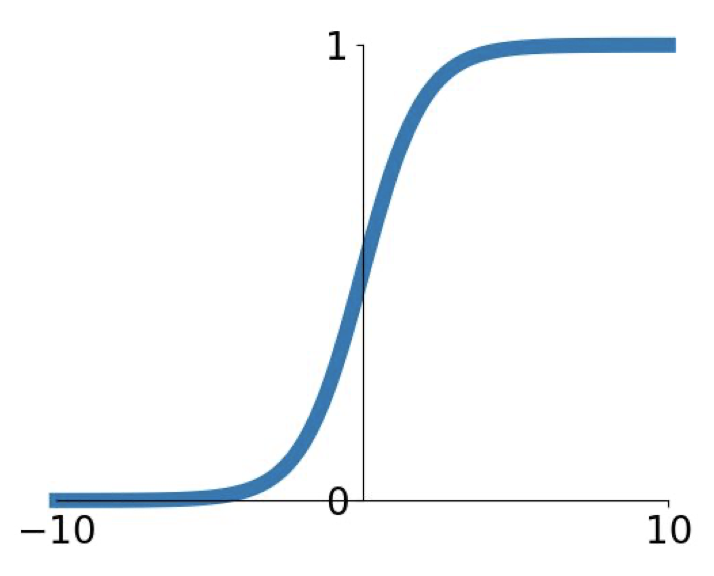 $\sigma(x)=1/(1+e^{-x})$
$\sigma(x)=1/(1+e^{-x})$
이 함수는 입력 데이터를 0과 1사이로 변환한다. 그러나 이 함수에는 치명적인 단점 3개가 존재하기 때문에 잘 사용되지 않는데, 3가지 단점은 다음과 같다.
- 입력 데이터가 특정 값을 넘어가거나 넘지 못하면 gradient가 0으로 수렴한다. 즉, gradient descent를 하지 못하기 때문에 역전파를 하지 못한다.
- 시그모이드 함수의 출력값의 중심이 0이 되지 않는다. 출력값의 중심이 0이 되지 않으면 가중치 행렬의 gradient가 모두 양수이거나 음수의 형태를 띄게된다. 이 말인즉슨 역전파를 할때 가중치 값이 모두 증가하거나 감소하여 최적의 가중치 행렬을 찾기 어렵다는 말이 된다.
- 자연함수 $e$ 가 들어가는 계산이므로 계산과정이 오래 걸린다.
tanh
tanh 함수의 모습은 다음과 같다.
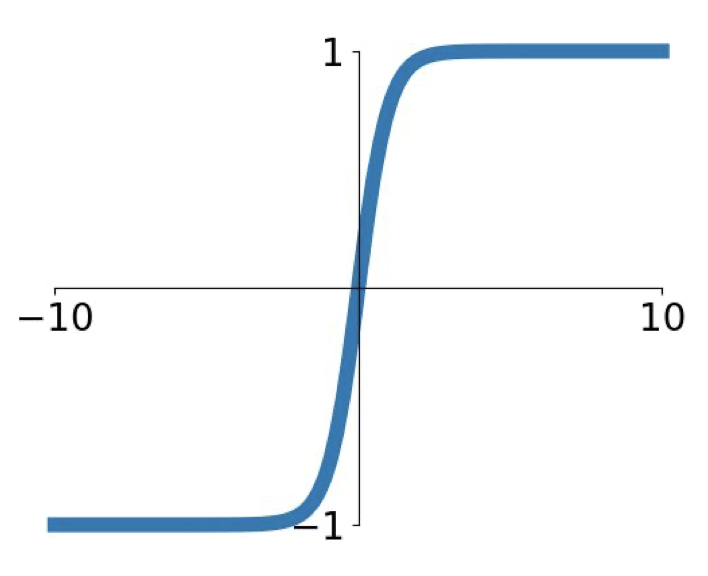
이 함수는 출력값의 중심이 0이 되지 않는다는 점만 제외하면 시그모이드 함수와 같은 단점을 가지고 있어 마찬가지로 자주 사용되지는 않는다.
ReLU
ReLU의 모습은 다음과 같다.
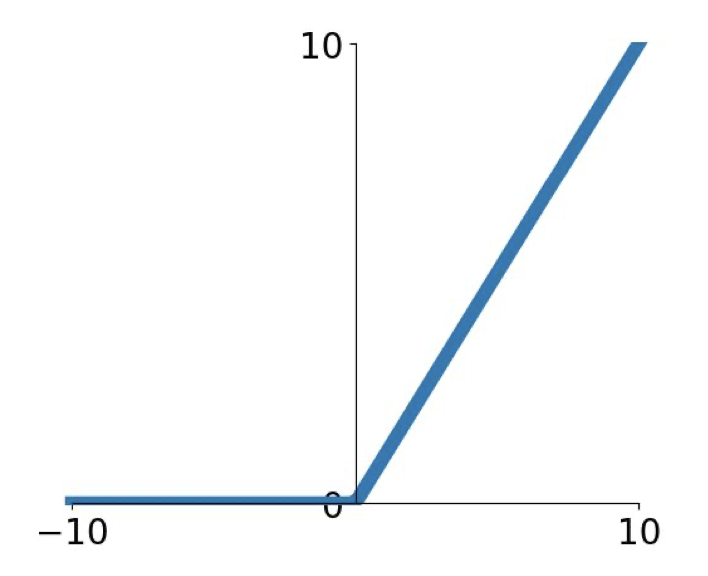 $f(x)=max(0,x)$
$f(x)=max(0,x)$
ReLU의 장점은 다음과 같다.
- 입력 데이터가 양수일때 gradient가 0로 수렴하지 않는다.
- 계산과정이 단순하고 빠르다.
- 실제 뉴런과 작동하는 방법이 비슷하다.
반면 단점은 다음과 같다.
- 입력 데이터가 음수일때 gradient가 0으로 수렴한다.
- 출력값의 중심이 0이 되지 않는다.
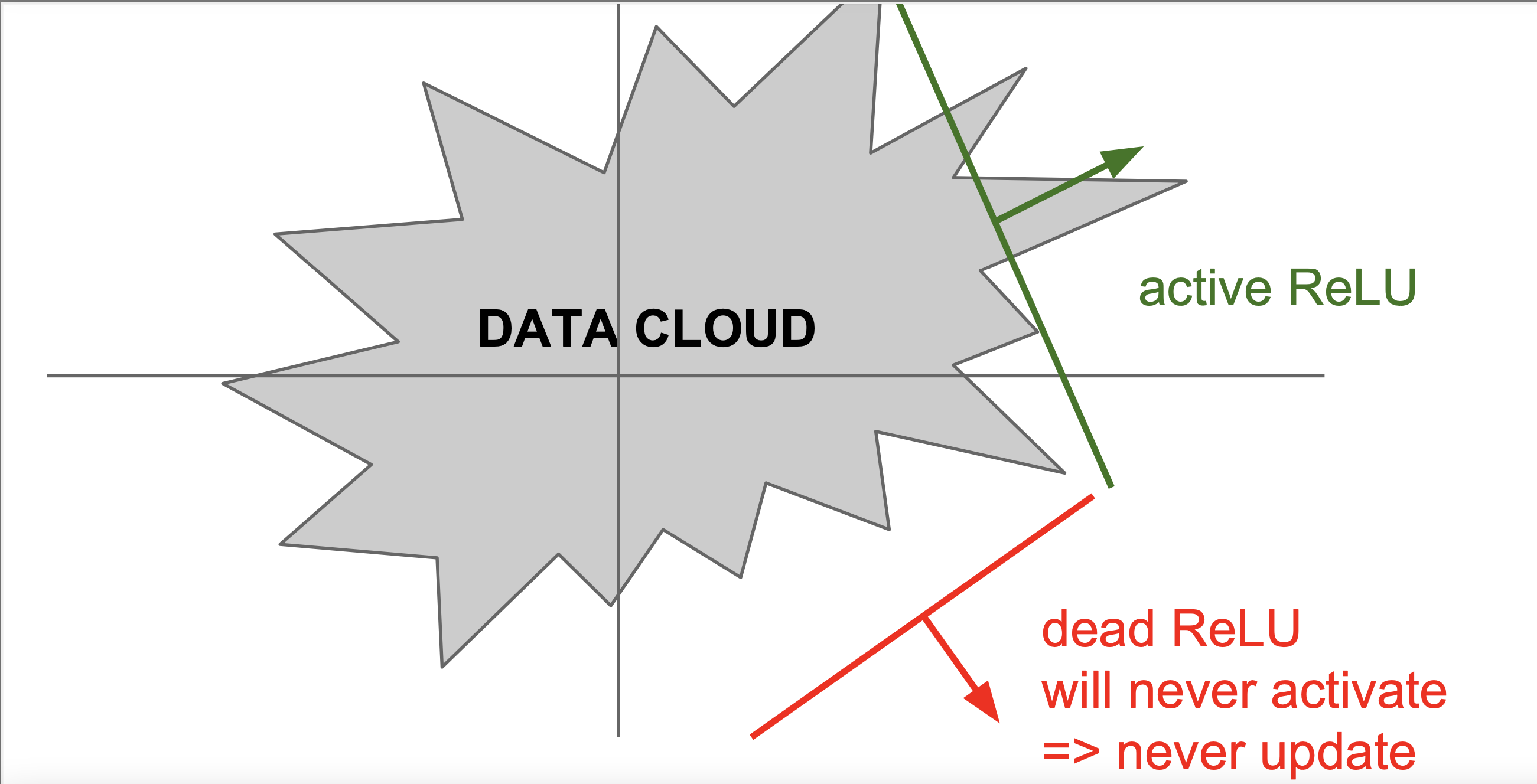
- 아래 사진과 같이 데이터들이 존재하는 지역 밖에 함수가 존재하면 dead ReLU, 즉 죽은 ReLU가 되어 더 이상 업데이트가 되지 않는 함수가 된다.
Leaky ReLU, PreReLU
Leaky ReLU의 모습은 다음과 같다.
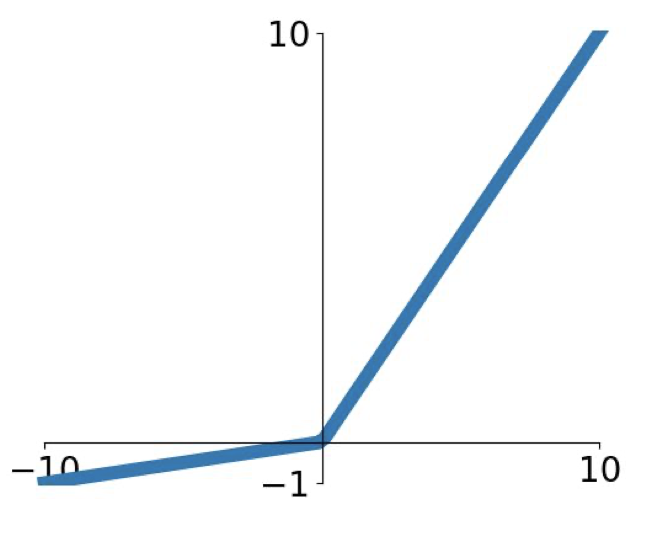 $f(x)=max(0.01x,x)$
$f(x)=max(0.01x,x)$
기본적인 형태는 ReLU와 비슷하나 ReLU에 비해 입력 데이터가 음수일때 gradient가 0으로 수렴하지 않는다는 장점을 가지고 있다.
PreReLU도 다음과 같이 ReLU와 비슷한 함수이다. $f(x)=max(\alpha x,x)$
여기서 $\alpha$는 역전파 과정을 통해 찾아나간다.
ELU
ELU의 모습은 다음과 같다.
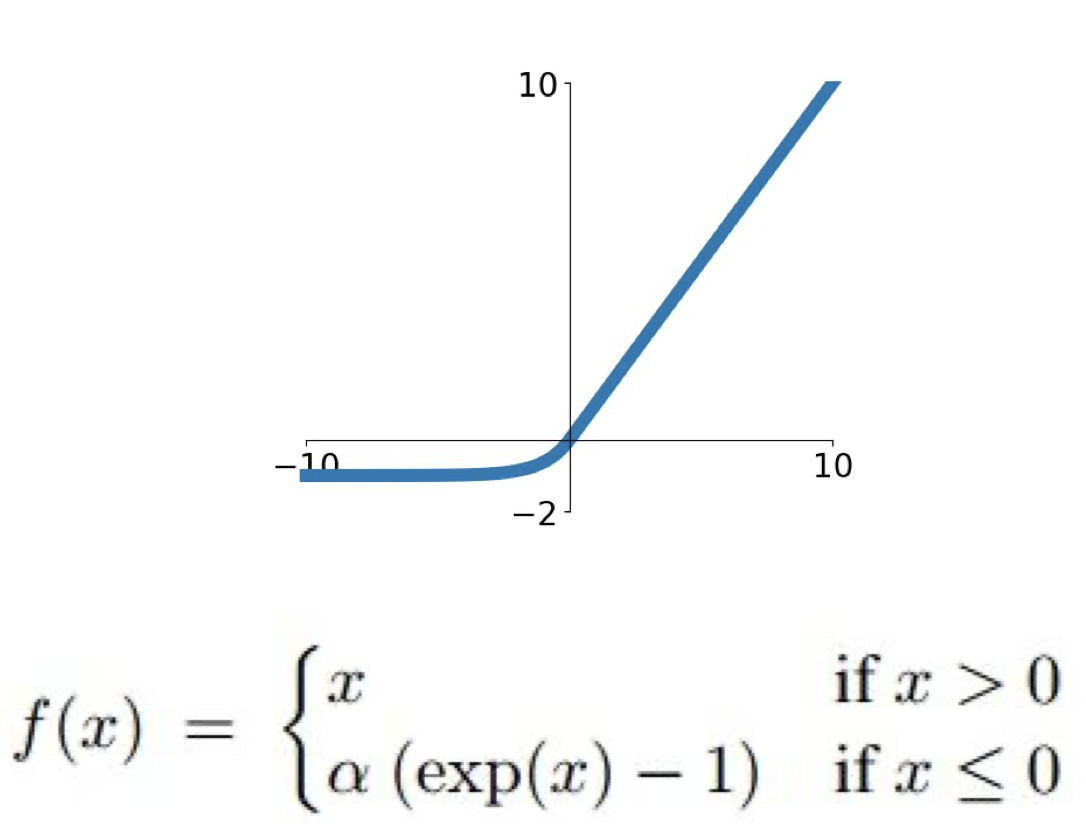
ReLU의 모든 장점을 공유하고 있으나 자연함수 $e$가 포함된 계산과정이 있기 때문에 계산하는 시간이 오래 걸린다는 단점이 있다.
Maxout
Maxout의 모습은 다음과 같다.
$max(w_1^{T}x+b_1,w_2^{T}x+b_2)$
이 함수는 ReLU와 LeakyReLU를 일반화하여 ReLU의 단점을 모두 극복한 것에 의의가 있다. 그러나 기존 ReLU의 계산과정의 두배가 된다는 점이 단점이다.
Choosing Activation Functions
어떠한 활성화 함수를 써야되는지에 대한 간단한 팁이다.
- 처음에는 ReLU 함수를 사용한다. 이때 learning rate를 잘 설정하는 것이 중요하다.
- 다음으로 Leaky ReLU, Maxout, ELU를 사용해본다.
- tanh는 한번쯤 시도해보나 결과에 대한 기대는 하지 않는 것이 좋다.
- sigmoid는 절대 사용하지 않는다.
Data Preprocessing
이미지를 훈련시키기 전에 전처리를 하는 것이 좋다. 추천되는 전처리 과정은 zero centering, 즉 데이터의 평균이 0이 되게 하는 것이다. 이때, 이미지 데이터의 분포와 크기를 보존하기 위해 정규화 과정은 잘 사용되지 않는다.
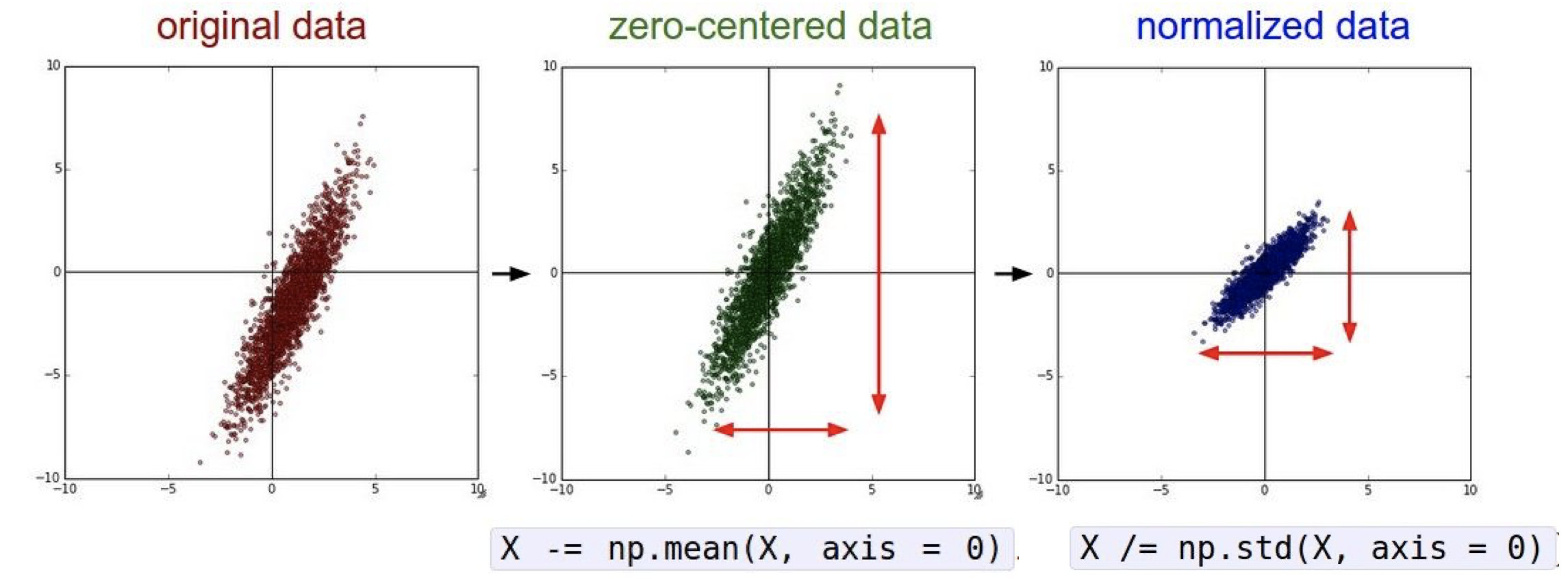
zero centering 외의 추천하는 전처리는 이미지의 차원을 줄이는 PCA, 분산을 1로 만드는 whitening 등이 있다.
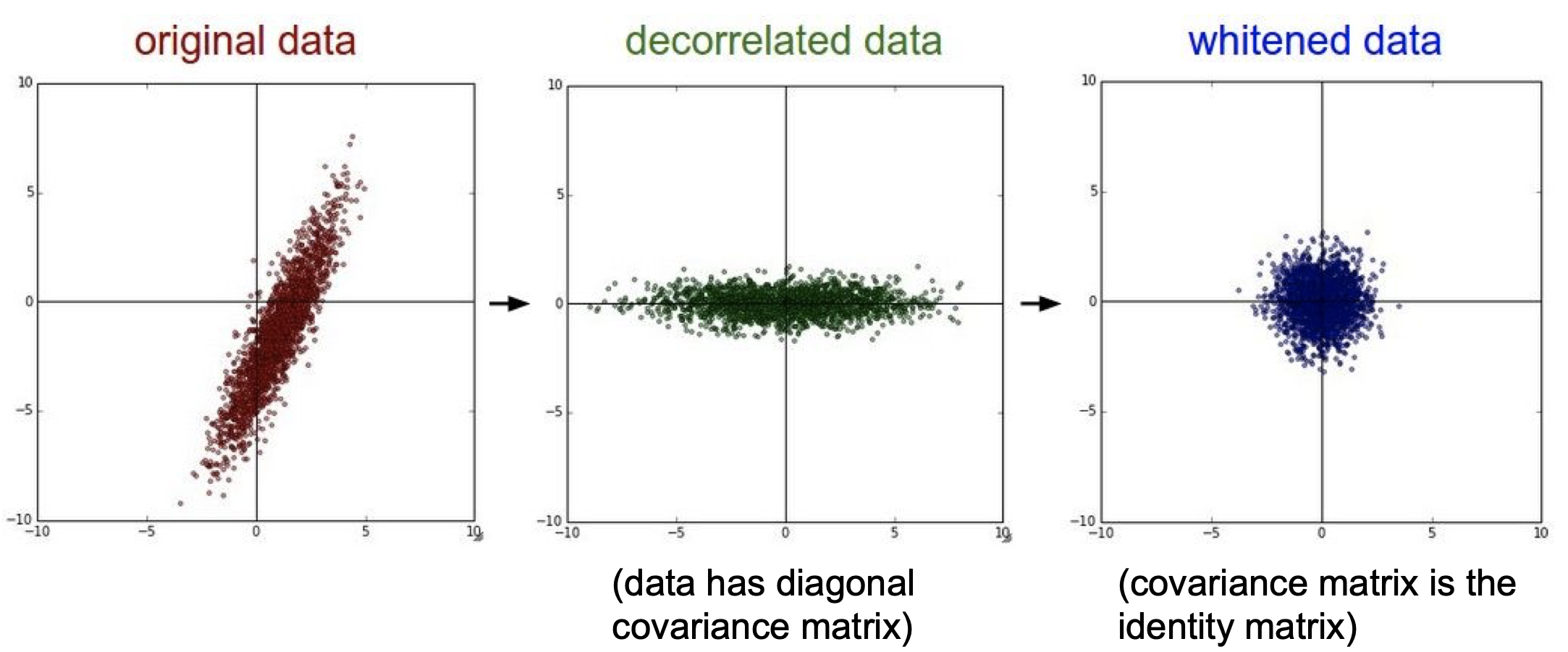
여기서 정규화를 위해 평균을 구하는 2가지의 다른 방법이 있다.
- 이미지의 차원은 생각하지 않고 각 픽셀의 평균을 구한다. (ex: AlexNet)
- 차원별로 각 픽셀의 평균을 구한다. (ex: VGGNet)
Weight initalization
정확한 훈련 모델을 만들기 위해 초기 가중치 값을 잘 설정하는 것은 매우 중요하다. 어떠한 값을 설정하는 것이 좋을지 여러가지 방법을 한번 살펴보자.
- 작은 랜덤 숫자로 설정한다
- 레이어가 중첩되며 가중치를 계속 곱했을때 표준편차가 0에 가까워지므로 좋은 방법이 아니다.
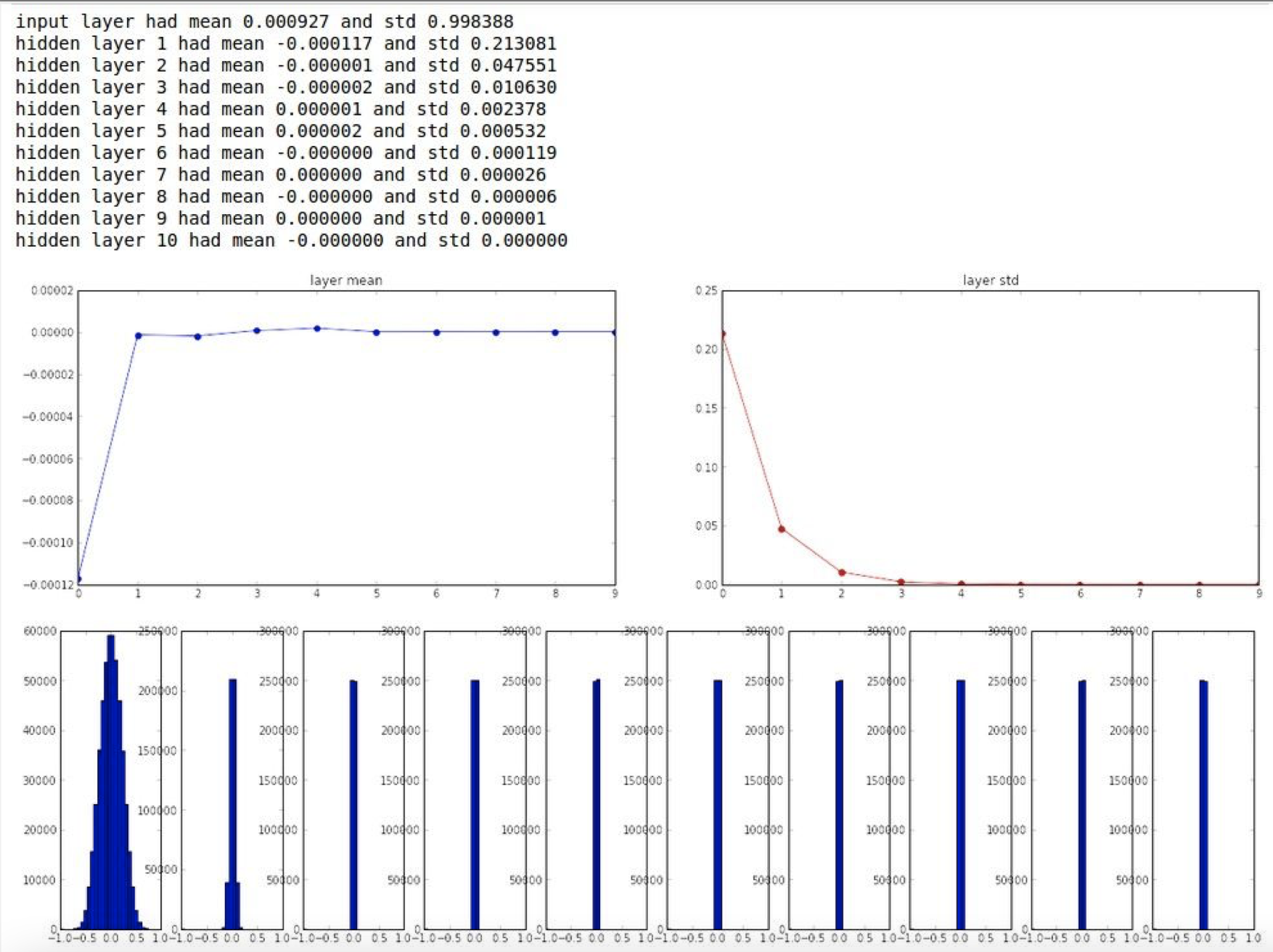
2. 큰 랜덤 숫자로 설정한다.
- 레이어가 중첩되며 가중치를 계속 곱했을때 표준편차가 -1 또는 1에 가까워지므로 좋은 방법이 아니다.
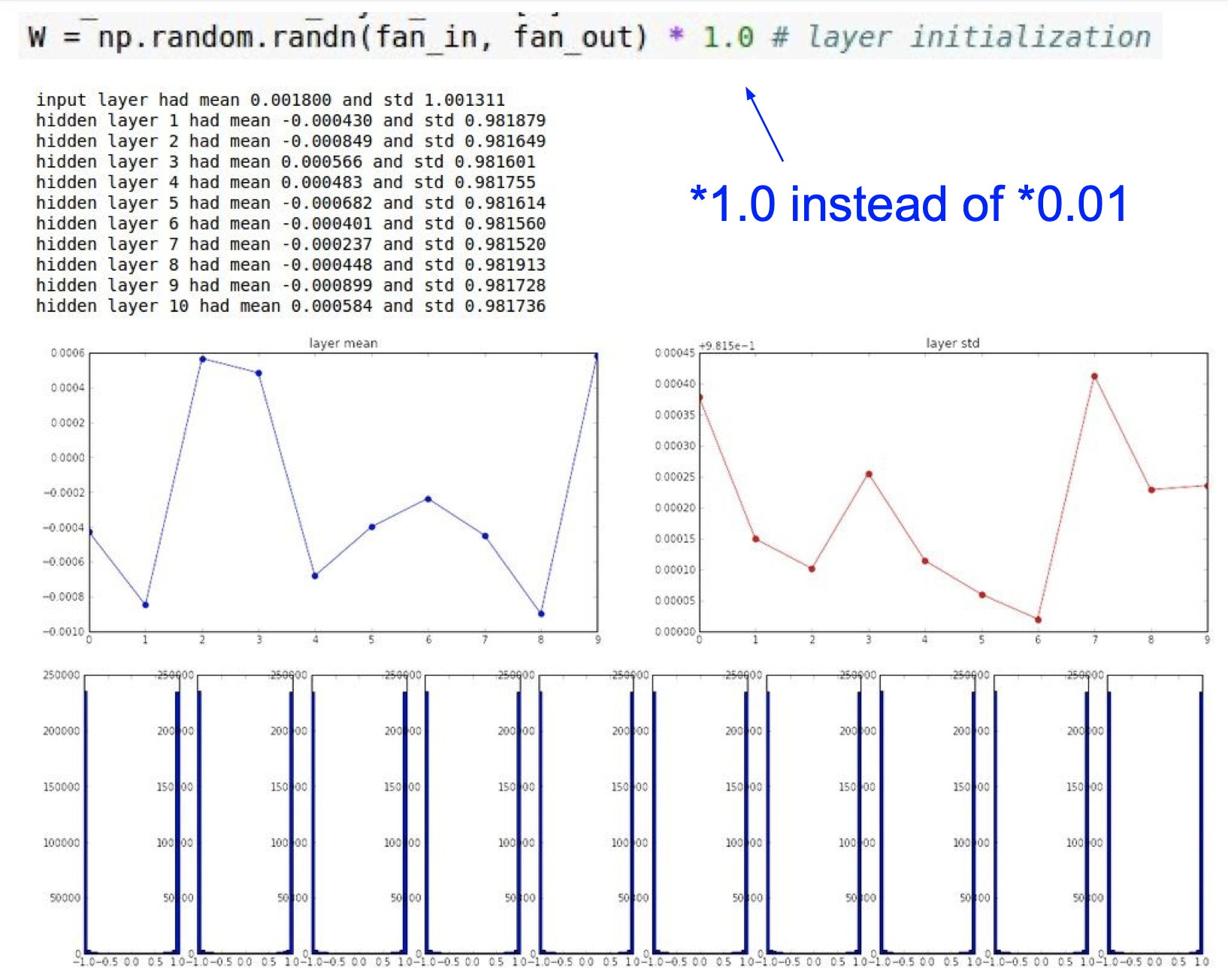
3. Xavier initalization
- 입력 데이터의 분산과 출력 데이터의 분산을 같게 만드는 방법이다.
- 출력 데이터의 크기가 크면 가중치의 값을 작게 설정하고, 출력 데이터의 크기가 작으면 가중치의 값을 크게 설정한다.
- 가장 이상적인 방법으로, 레이어를 중첩할수록 표준편차가 감소하며 특정 값으로 수렴하는 형태이다.
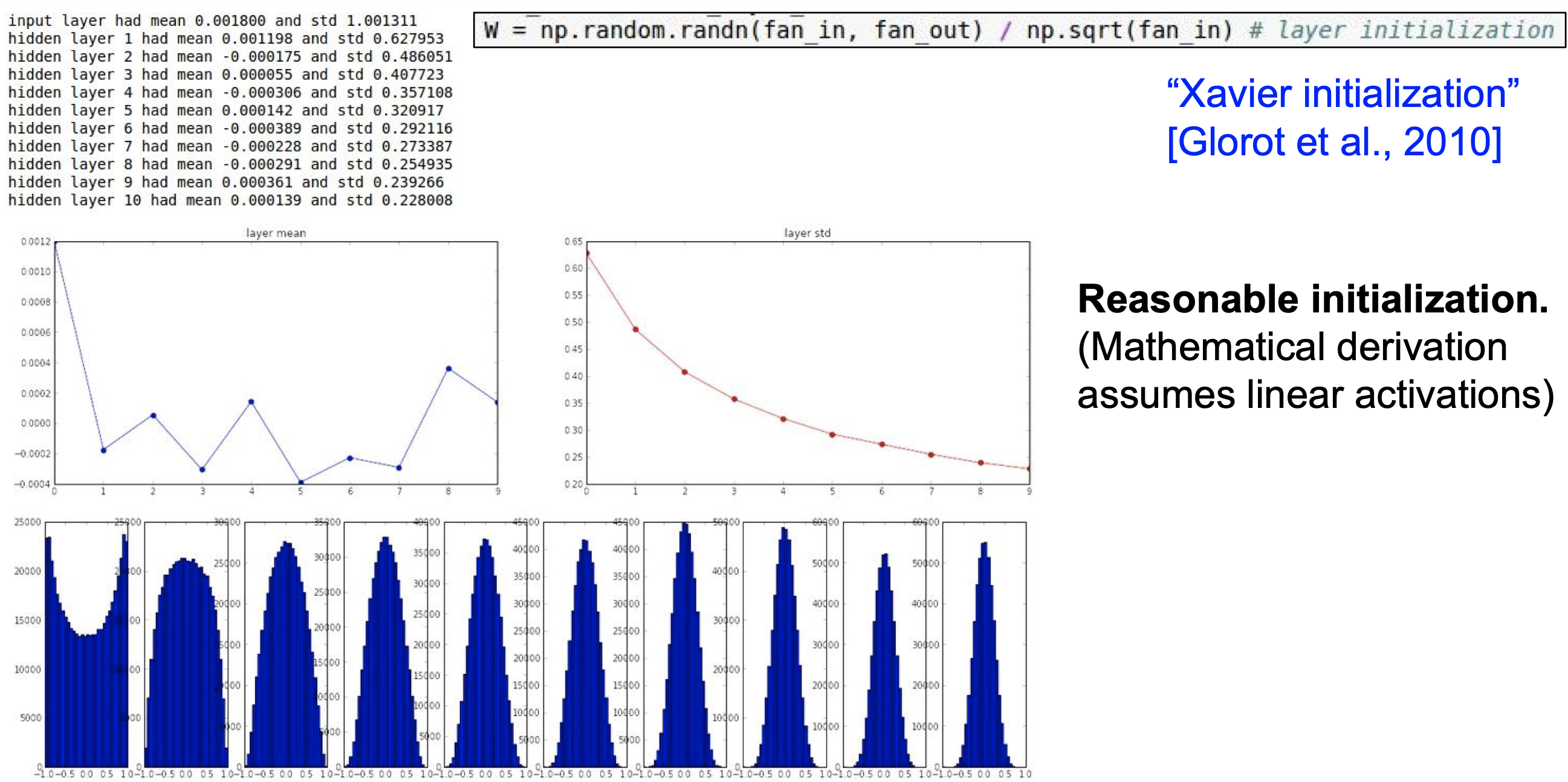
- ReLU를 사용할때는 입력 데이터를 2로 나누어야지 정상적으로 작동한다.

Batch Normalization
배치 정규화(Batch Normalization) 는 이미지를 학습하면서 데이터의 분포가 변형되지 않도록 하기 위한 방법이다. 일반 정규화와 다른 점은 차원별로 배치의 정규화를 한다는 것에 있다. 배치 정규화의 기본적인 공식은 다음과 같다.
$\hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}}$
배치 정규화는 주로 fully connected layer, convolutional layer 바로 다음에 이루어진다.
그리고 배치 정규화된 데이터를 다시 정규화 되기 전의 데이터로 변경해야되는 경우가 많이 생긴다. 따라서 이전 데이터를 복구하기 위한 변수인 $\gamma$ 와 $\beta$ 또한 배치 정규화 과정에서 계산한다.
$y^{(k)}=\gamma^{(k)} \hat{x}^{(k)}+\beta^{(k)}$
배치 정규화의 장점은 다음과 같다.
- gradient flow가 간단해진다.
- 높은 learning rate의 사용이 가능해진다.
- 초기 가중치 값 설정에 대한 부담을 덜어준다.
- dropout 사용의 필요성이 다소 감소한다.
아래 사진에 배치 정규화에 대해 배운 내용을 간단하게 정리한 내용이 나와있다.

Monitoring the training
이미지의 훈련은 다음과 같은 과정으로 이루어진다.
- 이미지 데이터를 전처리한다.
# zero-centering 방법을 이용
X -= np.mean(X, axis=0)
2. 훈련 모델의 구조를 설계한다. 이때, 층의 개수, 노드의 개수등을 정한다.
# 레이어의 수는 50개, 레이어당 노드 수는 10개로 설정한다.
3. 모델을 훈련시킨다. 이때, 정직화(regularization)값은 0, learning rate는 적당히 작게 설정한다. 또한 이미지 데이터의 일부에 과적합 할 수 있도록 20개의 데이터만 훈련시킨다.
model = init_two_layer_model(32*32*3,50,10) #input size, hidden layer size, number of classes
trainer = ClassifierTrainer()
X_tiny = X_train[:20] # 20개의 데이터만 훈련시킨다.
y_tiny = y_train[:20]
best_model, stats = trainer.train(X_tiny,y_tiny,X_tiny,y_tiny,
model,two_layer_net,
num_epochs=200, reg=0.0,
update='sgd', learning_rate_decay=1,
sample_batch=False,
learning_rate=1e-3, verbose=True)
위 코드를 실행시키면 다음과 같이 epoch별 훈련 결과가 나온다.
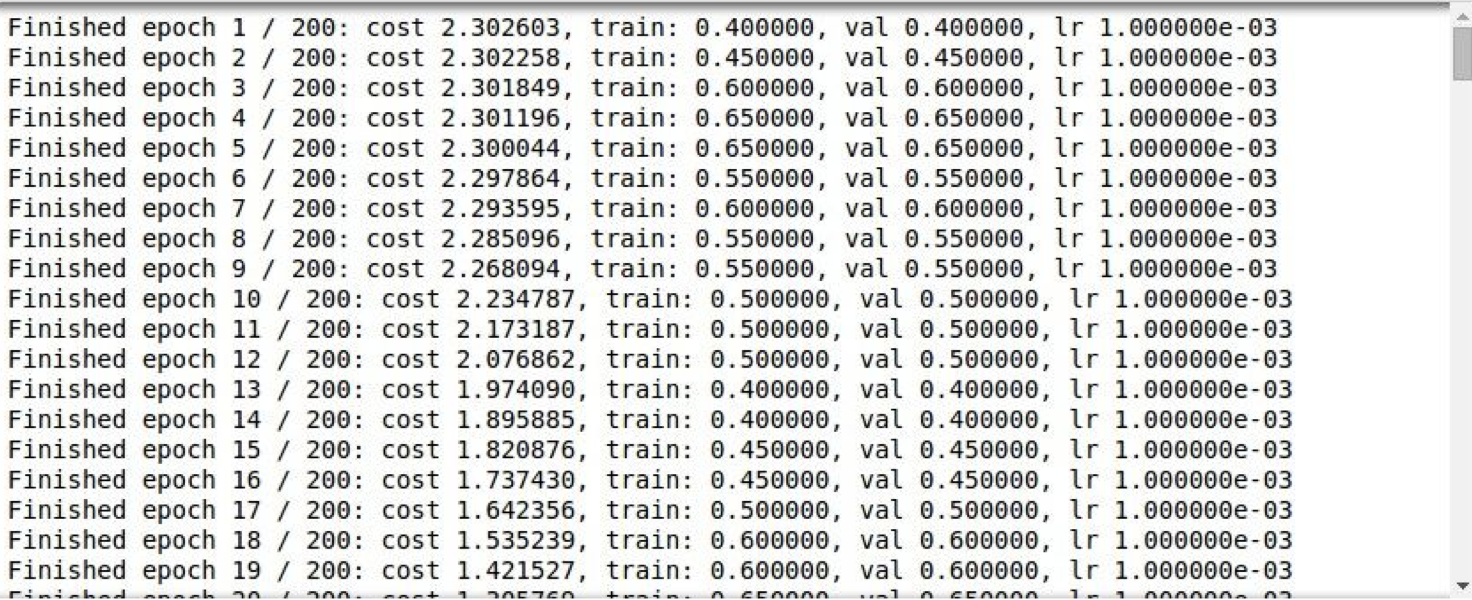
훈련을 진행할수록 손실값(cost)은 감소하고 정확도(train)은 증가하여 훈련이 정상적으로 이루어지고 있다는 사실을 확인할 수 있다.
4. 정직화 값을 변경하고 learning rate 값을 더 작게 설정하여 모델을 다시 훈련시켜본다.
model = init_two_layer_model(32*32*3,50,10) #input size, hidden layer size, number of classes
trainer = ClassifierTrainer()
best_model, stats = trainer.train(X_train,y_train,X_val,y_val,
model,two_layer_net,
num_epochs=10, reg=0.000001,
update='sgd', learning_rate_decay=1,
sample_batch=True,
learning_rate=1e-6, verbose=True)
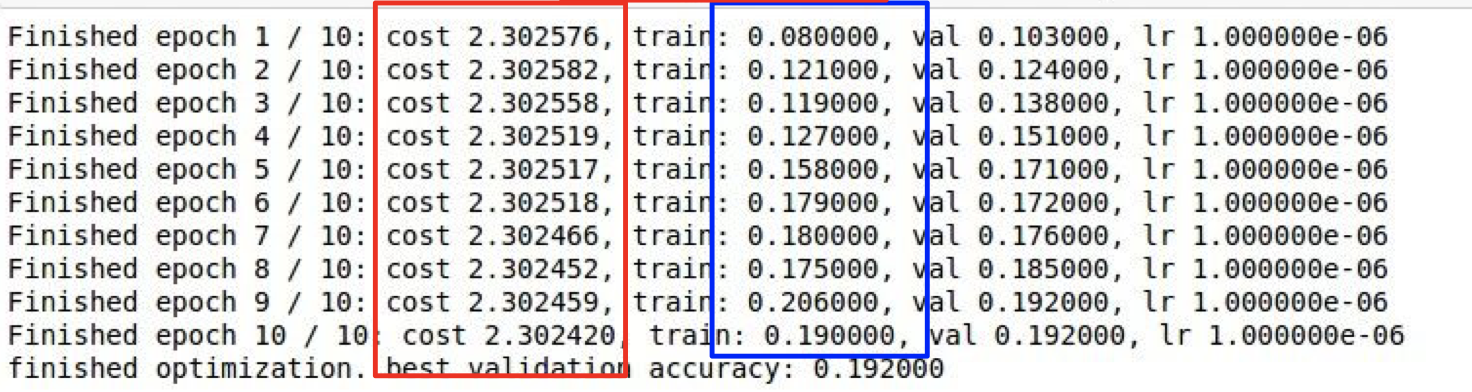
훈련이 진행할수록 손실값과 정확도 값이 거의 그대로 인것을 확인할 수 있다. 이러한 현상은 learning rate을 너무 낮게 하였기 때문이다.
5. 그렇다면 learning rate를 크게 설정하여 모델을 다시 훈련시켜보자.
model = init_two_layer_model(32*32*3,50,10) #input size, hidden layer size, number of classes
trainer = ClassifierTrainer()
best_model, stats = trainer.train(X_train,y_train,X_val,y_val,
model,two_layer_net,
num_epochs=10, reg=0.000001,
update='sgd', learning_rate_decay=1,
sample_batch=True,
learning_rate=1e6, verbose=True)

손실값이 NaN이 나왔다. 이러한 현상은 learning rate가 지나치게 크게 설정되었기 때문에 나타나였다.
Hyperparameter Optimization
Cross validation
최적의 parameter을 찾기 위한 과정으로 교차 검증(cross-validation)가 있다. 정직화 변수와 learning rate 변수를 일정한 범위로 설정한 후 그 범위 안에서 가장 좋은 성능을 보이는 모델의 parameter을 찾는 방법이다.
max_count = 100
for count int xrange(max_count):
reg = 10**uniform(-4,0)
lr = 10**uniform(-3,-4)
trainer = ClassifierTrainer()
model = init_two_layer_model(32*32*3,50,10) #input size, hidden layer size, number of classes
trainer = ClassifierTrainer()
best_model_local, stats = trainer.train(X_train,y_train,X_val,y_val,
model,two_layer_net,
num_epochs=5, reg=reg,
update='momentum', learning_rate_decay=0.9,
sample_batches=True, batch_size=100,
learning_rate=lr, verbose=True)
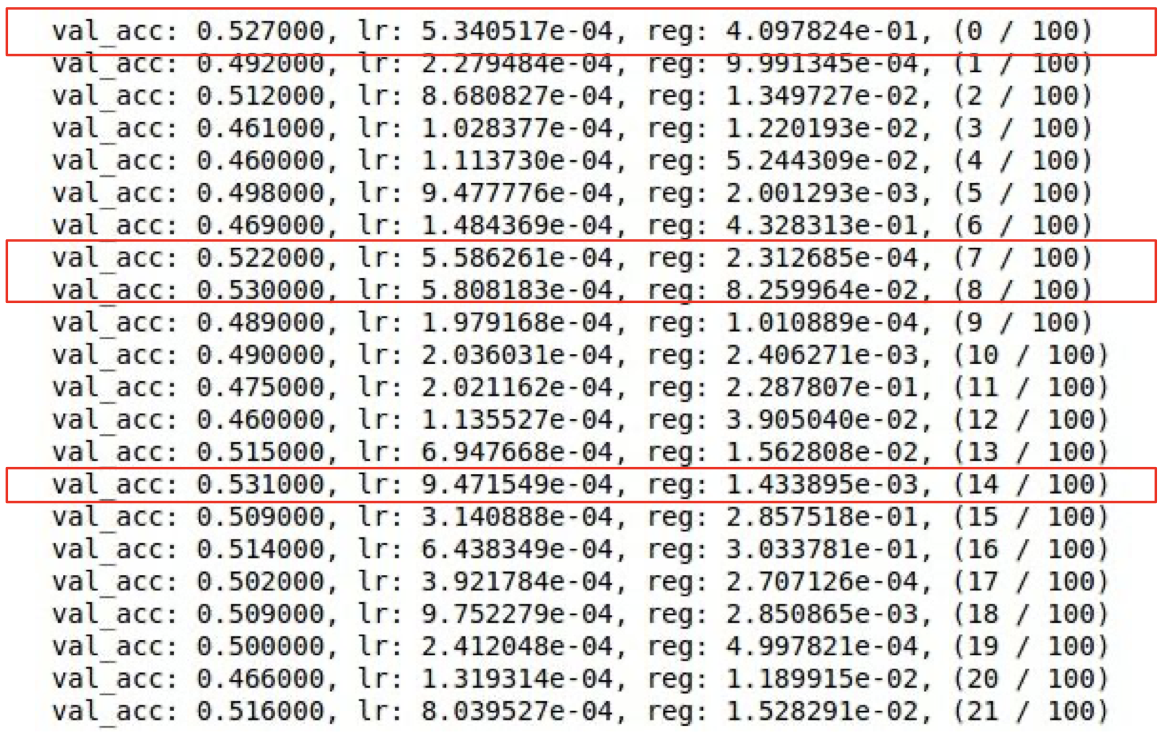
빨간색 박스가 쳐진 모델의 검증 데이터의 정확도(val_acc)가 높게 나타나 이 모델에 사용된 정직화 변수와 learning rate 변수를 범위로 지정해 다시 교차검증을 실시할 수 있다.
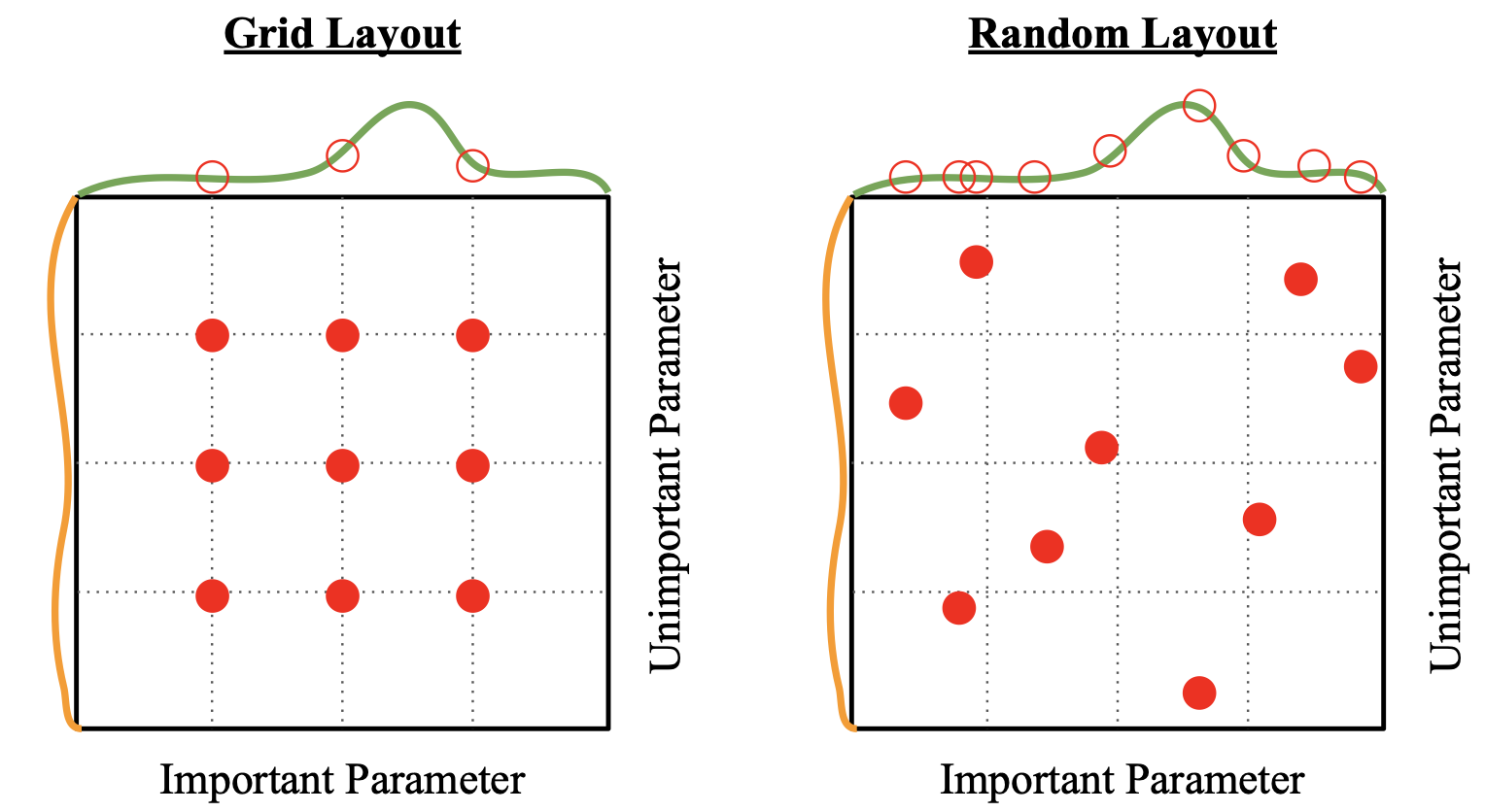
Random search
이전 단원에서 랜덤서치(Random search)는 상당히 무식하고 잘 쓰이지 않는 알고리즘이라고 한적이 있다. 그러나 이미지 데이터를 훈련시킬때는 랜덤서치가 상당히 유용할 수 있는데, 일정한 규칙에 따라 정렬된 parameter보다 완전히 랜덤한 parameter을 쓰는 것이 예상치 못하게 더 효과적인 결과를 보일수 있기 때문이다.
Visualization of loss curve
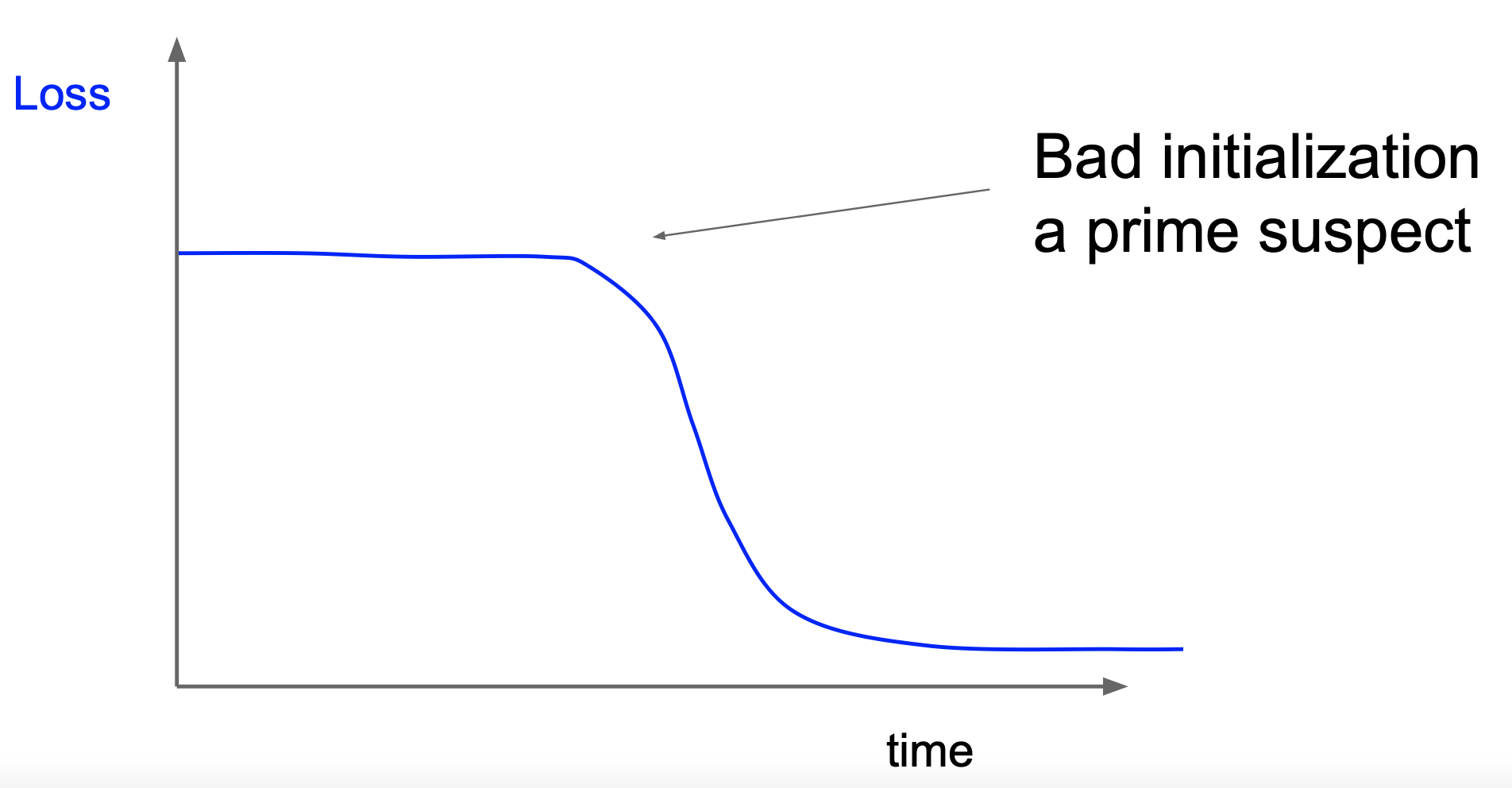
다음은 learning rate를 어떻게 설정하느냐에 따라 나타나는 손실값을 그래프로 표현한 것이다.
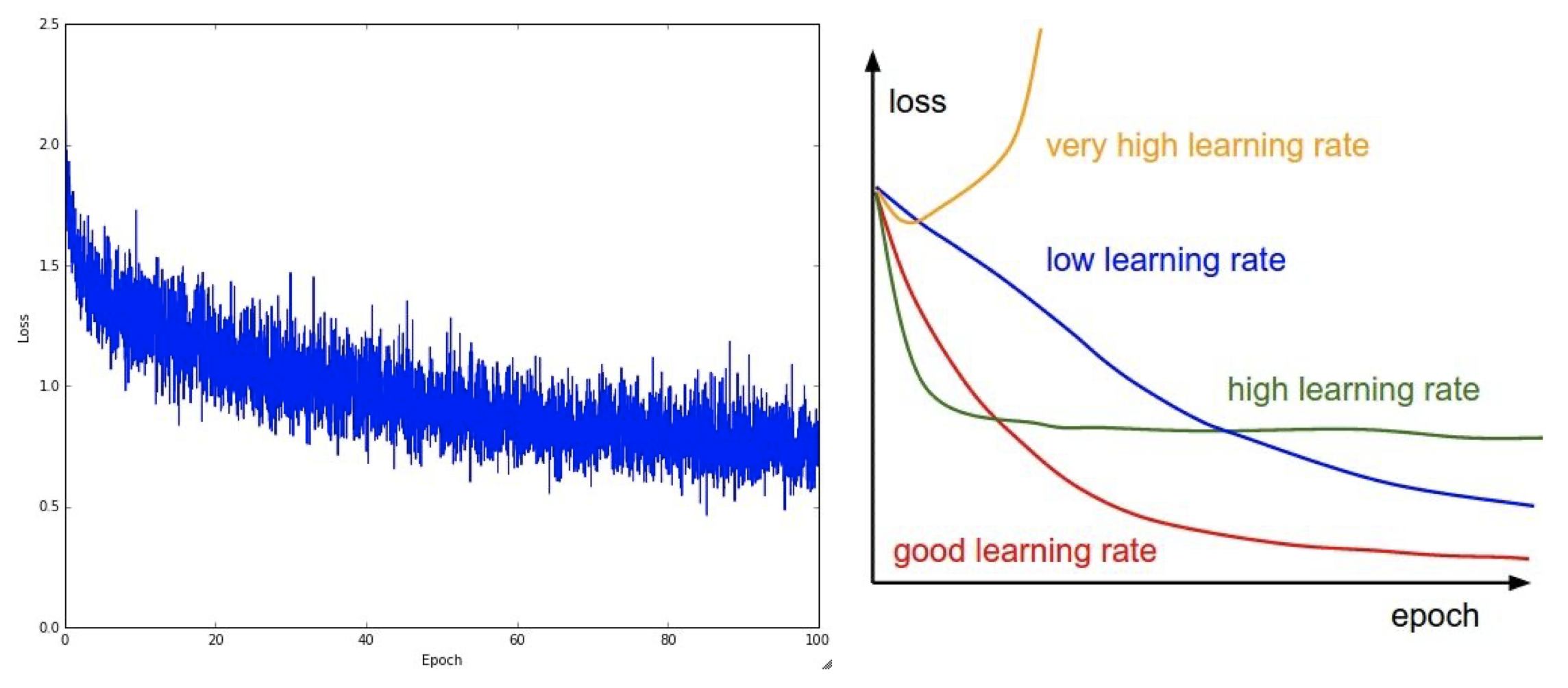
만약 아래 사진과 같이 loss 값이 한동안 일정하면 초기 가중치 값을 잘못 설정하였다는 의미이다.
아래 그래프를 한번 보자. 빨간색 그래프와 초록색 그래프의 차이가 큰 경우는 훈련 데이터에 지나치게 과적합하여 정직화 과정이 필요한 경우이다.
Summary
- 활성화 함수는 ReLU를 사용한다.
- 전처리과정은 zero-centering 방법을 이용한다.
- 초기 가중치 값 설정은 Xavier initalization 방법을 이용한다
- 배치 정규화를 사용하는 것을 추천한다.
- 최적의 parameter를 찾기 위한 방법으로 교차 검증을 이용하나, 가능하면 랜덤 서치도 시도해본다.
Comments