
Chapter 4: 모델 구축 part1
챕터4는 데이터의 생성된 특징을 바탕으로 모델을 구축하는 방법에 대해 설명하고 있다. 이 장 또한 양이 상당히 많고 중요한 내용을 담고 있기 때문에 두 개의 파트로 나눠서 정리하기로 하였다.
4.1 모델의 기본 이해
4.1.1 모델이란?
모델이란 특징을 입력 데이터로 사용해 예측값을 만들어 내는 것이다. 경진대회의 대부분은 지도학습에 해당 되므로 이 장에서는 지도 학습 모델에 대해서만 설명하고 있다.
4.1.2 모델 구축의 흐름
모델 학습과 예측은 다음과 같은 순서로 실시한다.
- 모델 종류를 선택하고 하이퍼파라미터를 지정
- 학습 데이터와 목적변수를 제공하여 학습을 진행
- 테스트 데이터를 제공하여 예측
이 때, 모델을 만들어 갈 때 모델의 좋고 나쁨을 평가해야 한다. 만약 모델의 기반이 된 학습 데이터를 그대로 평가에 이용하면 정답률이 100% 가 되므로 학습 데이터 중 일부 데이터를 평가용 데이터로 분류 해야한다. 이러한 방법을 검증(validation) 이라고 한다. 다음은 검증의 대표적인 방법인 k 교차 검증(k-cross validation) 방법을 통해 검증을 실시하는 코드이다.
# -----------------------------------
# 교차 검증(crossvalidation)
# -----------------------------------
from sklearn.metrics import log_loss
from sklearn.model_selection import KFold
# 학습 데이터를 4개로 나누고 그 중 1개를 검증 데이터로 지정
# 분할한 검증 데이터를 바꾸어가며 학습 및 평가를 4회 실시
scores = []
kf = KFold(n_splits=4, shuffle=True, random_state=71)
for tr_idx, va_idx in kf.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
model = Model(params)
model.fit(tr_x, tr_y)
va_pred = model.predict(va_x)
score = log_loss(va_y, va_pred)
scores.append(score)
특징의 추가 및 변경, 모델 종류의 선택, 하이퍼파라미터의 선택은 서로 긴밀하게 연결되어 있다. 다음은 이 세가지 과정을 진행하는 과정에서의 중요한 팁이다.
- 특징이 제일 중요하므로 경진 대회의 주어진 시간의 대부분을 특징 생성에 할애한다.
- 하이퍼파리터를 변경했을 때 얼마나 영향을 주는지 살펴보다가 대회 후반부터 본격 조정한다.
- 모델은 처음에는 GBDT 로 진행하다가 문제의 성질에 따라 신경망을 검토하거나, 앙상블을 고려할 때는 다른 모델로도 구축을 해본다.
- 검증 구조를 변경해가며 학습을 시키기도 한다.
- Public Leaderboard 에만 집착하면 과적합 할 수 있으므로 과적합에 유의하도록 한다.
4.1.3 모델 관련 용어와 팁
모델을 만들거나 그 사용 방법을 이해하는데 도움이 될 만한 용어와 팁들이다.
- 과적합
- 학습 데이터의 노이즈까지 학습하여 학습 데이터 이외의 데이터에서 점수가 좋지 않은 현상을 과대적합(overfitting)이라고 한다.
- 반대로 학습 데이터의 성질을 충분히 학습하지 않아 학습 데이터에서도 점수가 좋지 않으면 과소적합(underfitting) 이라고 한다.
- 정규화
- 학습 모델에 제약을 부여해 복잡성을 제어하는 것을 정규화(regularization) 라고 한다.
- 학습 데이터와 검증 데이터의 점수 모니터링
- 학습이 순차적으로 진행되는 모델에서는 학습 데이터와 목적변수 외에도 모니터링할 평가지표 및 검증 데이터와 그 목적변수를 전달함으로써 학습 데이터와 검증 데이터 각각의 점수 추이를 볼 수 있다.
- 조기종료
- 조기 종료(early stopping)란 학습 시 검증 데이터의 점수를 모니터링하다가 일정 시간 동안 점수가 오르지 않으면 중간에 학습을 중단하는 기능이다.
- 조기 종료는 학습 데이터의 점수가 과적합 되어 일반화 성능이 떨어지는 것을 방지하는 목적으로 사용한다.
- 학습이 진행하면서 학습 데이터의 점수는 계속 좋아지는 반면 검증 데이터의 점수는 일정한 선에서 멈추게 된다.
- 배깅
- 배깅(bagging) 이란 여러 모델을 조합해 모델을 구축하는 방법 중 하나이다. 같은 종류의 모델을 여러 개 병렬로 구축하고, 이 예측값들의 평균 또는 최빈값을 이용해 예측한다.
- 좁은 의미로는 부트스트랩 샘플, 넓은 의미로는 랜덤 포레스트 등의 모델이 있다.
- 부스팅
- 부스팅(boosting) 이란 여러 모델을 조합해 모델을 구축하는 방법 중 하나이다. 같은 종류의 모델을 직렬 조합하고 학습을 통해 예측값을 보정해 순서대로 하나씩 모델을 학습시킨다.
- GBDT 가 부스팅을 사용하는 대표적인 모델 중 하나이다.
4.2 경진 대회에서 사용하는 모델
정형 데이터를 다루는 경진대회에서 사용하는 모델은 다음과 같다.
- GBDT
- 신경망
- 선형 모델
- 기타 모델 (k-최근접 이웃 알고리즘)
- 랜덤 포레스트
- 익스트림 랜덤 트리
- RGF, FFM
모델의 대체적인 선택 순서는 다음 그림에 나타나 있다.
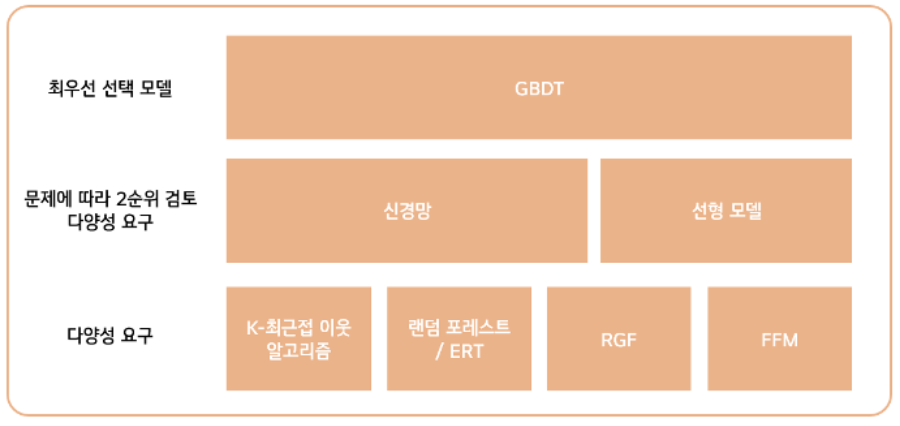
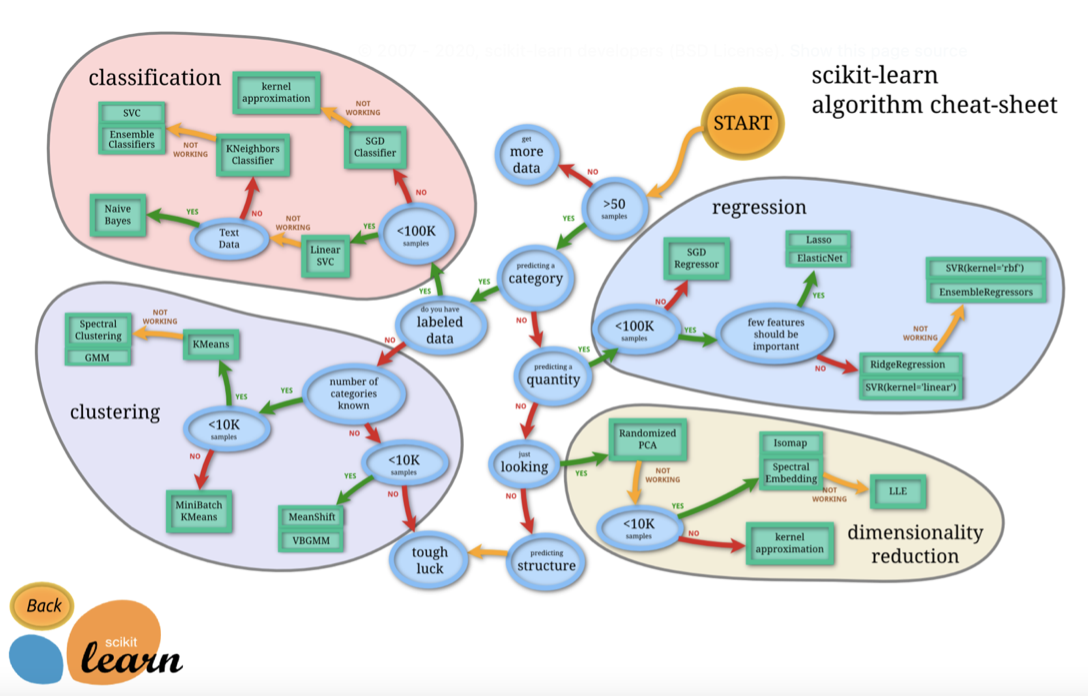
다음은 조금 더 세세한 조건에 맞게 모델을 선택하는 순서를 나타낸 그림이다.
4.3 GBDT
4.3.1 GBDT의 개요
GBDT는 Gradient Boosting Decision Tree (그래디언트 부스팅 결정 트리)의 약자로, 모델의 사용 편의성과 성능이 높아 경진대회에서 자주 사용된다. GBDT는 다수의 결정 트리로 이루어져 있는데, 각 결정트리의 분기 및 잎의 가중치가 정해지는 과정으로 모델이 만들어진다. 이 때, 목적변수와 예측값의 오차를 줄여나가며 목적함수를 개선시킨다. 이 과정은 하이퍼파라미터에서 정한 결정트리의 개수만큼 반복한다. 랜덤 포레스트는 결정 트리를 병렬로 작성해나가는 반면 GBDT는 직렬로 작성해가며 직전까지 작성한 결정 트리의 예측값을 새로운 결정 트리의 예측값에 반영해가며 조금씩 수정해 나간다.
4.3.2 GBDT의 특징
GBDT의 특징은 다음과 같다.
- 특징은 수치로 표현해야 한다.
- 결측값을 다룰 수 있다.
- 변수 간 상호작용이 반영된다.
다른 모델에 비해 갖는 장점은 다음과 같다.
- 모델 성능이 높다.
- 매개변수 튜닝을 하지 않아도 모델 성능이 잘 나온다.
- 불필요한 특징을 추가해도 모델 성능이 떨어지지 않는다.
- 특징값의 범위를 스케일링 할 필요가 없다.
- 범주형 변수를 원-핫 인코딩 할 필요가 없다.
- 희소행렬에 대응한다.
4.3.3 GBDT의 주요 라이브러리
GBDT에서 사용되는 라이브러리는 다음과 같다.
- xgboost: 제일 오래 사용된 GBDT 라이브러리로, 오래된 만큼 관련 정보와 자료가 많이 있다.
- lightgbm: xgboost 와 상당히 가까운 예측 알고리즘을 갖고 있으며, 성능이 높고 연산 속도가 빨라 인기가 높다.
- catboost: 범주형 특징이 있는 데이터를 다루는데 효과적이다.
- GradientBoostingRegressor/ GradientBoostingClassifier: xgboost 보다 모델 성능, 연산 속도 모두 떨어지므로 자주 사용되지 않는 모델이다.
4.3.4 GBDT의 구현
다음은 xgboost를 이용하여 모델링을 하는 코드이다.
# -----------------------------------
# xgboost의 구현
# -----------------------------------
import xgboost as xgb
from sklearn.metrics import log_loss
# 특징과 목적변수를 xgboost의 데이터 구조로 변환
dtrain = xgb.DMatrix(tr_x, label=tr_y)
dvalid = xgb.DMatrix(va_x, label=va_y)
dtest = xgb.DMatrix(test_x)
# 하이퍼파라미터 설정
params = {'objective': 'binary:logistic', 'silent': 1, 'random_state': 71}
num_round = 50
# 학습의 실행
# 검증 데이터도 모델에 제공하여 학습 진행과 함께 점수가 어떻게 달라지는지 모니터링
# watchlist로 학습 데이터 및 검증 데이터를 준비
watchlist = [(dtrain, 'train'), (dvalid, 'eval')]
model = xgb.train(params, dtrain, num_round, evals=watchlist)
# 검증 데이터의 점수를 확인
va_pred = model.predict(dvalid)
score = log_loss(va_y, va_pred)
print(f'logloss: {score:.4f}')
# 예측 - 두 값(0 or 1)의 예측이 아닌 양성(1)일 확률을 출력
pred = model.predict(dtest)
4.3.5 xgboost 사용 팁
다음은 xgboost를 사용할때 사용할 수 있는 유용한 팁이다.
- xgboost 의 booster 매개변수에서 어떠한 모델을 사용할지 선택할 수 있다. GBDT를 사용하기 위해서는 gbtree, 선형모델을 사용하기 위해서는 gblinear, DART라는 알고리즘을 사용하기 위해서는 dart 로 설정한다.
- xgboost는 목적함수를 최소화하는 방법으로 학습을 진행한다. 매개변수는 objective이며, 회귀에는 reg:squarederror, 이진 분류에는 binary:logistic, 다중 클래스 분류에는 multi:softprob 으로 설정해준다.
- 학습률, 결정 트리의 깊이, 정규화 강도 등을 하이퍼파라미터로 지정할 수 있다.
- train 메서드의 evals 매개변수 에 학습 데이터와 검증 데이터를 넘겨주어 결정 트리를 추가할 때마다 이들 데이터에 대한 점수를 출력하게 할 수 있다.
- train 메서드의 early_stopping_rounds 매개변수를 지정함으로써 조기 종료를 할 수 있다.
- 모델 훈련시의 Learning API의 train 메서드와 Scikit-Learn API의 scikit-learn 클래스 중에 선택할 수 있다.
4.3.6 lightgbm
lightgbm은 xgboost와 비교하여 모델성능은 비슷하나 연산 속도는 확실히 더 빠르다는 장점을 가지고 있는 라이브러리이다. lightgbm의 특징은 다음과 같다.
- 히스토그램 기반의 결정 트리 분기에 따른 고속화가 가능하다.
- 깊이 단위가 아닌 잎 단위에서의 분기 추가에 따른 모델 성능 향상이 이루어진다. 깊이 단위에서의 분기 추가와 잎 단위에서의 분기 추가의 차이는 다음 그림과 같다.
- 범주형 변수의 분할 최적화로 모델 성능의 향상이 이루어진다.
다음은 lightgbm을 이용하여 모델링을 하는 코드이다.
# -----------------------------------
# lightgbm의 구현
# -----------------------------------
import lightgbm as lgb
from sklearn.metrics import log_loss
# 특징과 목적변수를 lightgbm의 데이터 구조로 변환
lgb_train = lgb.Dataset(tr_x, tr_y)
lgb_eval = lgb.Dataset(va_x, va_y)
# 하이퍼파라미터 설정
params = {'objective': 'binary', 'seed': 71, 'verbose': 0, 'metrics': 'binary_logloss'}
num_round = 100
# 학습 실행
# 범주형 변수를 파라미터로 지정
# 검증 데이터도 추가 지정하여 학습 진행과 함께 점수가 어떻게 달라지는지 모니터링
categorical_features = ['product', 'medical_info_b2', 'medical_info_b3']
model = lgb.train(params, lgb_train, num_boost_round=num_round,
categorical_feature=categorical_features,
valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval])
# 검증 데이터에서의 점수 확인
va_pred = model.predict(va_x)
score = log_loss(va_y, va_pred)
print(f'logloss: {score:.4f}')
# 예측
pred = model.predict(test_x)
4.3.7 catboost
catboost의 특징은 다음과 같다.
- 범주형 변수로서 지정한 특징을 자동으로 타깃 인코딩하여 수치로 변환한다.
- 각 깊이별 분기 조건식에 모두 망각 결정 트리(oblivious decision tree)가 사용된다.
- 데이터 수가 적을 때는 정렬 부스팅이라는 알고리즘이 사용된다.
- 속도가 느려 xgboost나 lightgbm에 비해 많이 쓰이지는 않으나 상호작용이 중요한 경우 모델 성능이 잘 나오는 경우가 있어 사용할 가치가 있다.
Comments