
데이콘 경진대회 참여후기 part1
지금까지의 배운 내용을 실전에 한번 적용해보고 싶다는 생각에 동아리 스터디원들과 함께 데이콘 경진대회에 참여 하였다. 대회의 내용은 구내식당 식수 인원을 예측하는 것으로, 대회 기간은 6월 3일부터 7월 23일까지였으며 대회 종료한지는 2달(…)이 넘게 지난 지금 경진대회 참여 후기를 작성하려고 한다.
데이터의 특징
경진대회에서 train, test, sample_submission 이렇게 3개의 데이터가 주어졌다. 이 데이터에서의 목적변수는 중식계와 석식계이고 나머지 주어진 특징으로는 일자, 요일, 본사정원수, 본사휴가자수, 본사출장자수, 본사시간외근무명령서승인건수, 현본사소속재택근무자수, 조식메뉴, 중식메뉴, 석식메뉴이 있었다.
데이터 분석
사실 나는 데이터 분석을 별로 신경쓰지 않았다. 내가 스터디한 내용 중에 데이터 분석을 집중적으로 다루는 파트가 없기도 했거니와 데이터 분석으로부터 특징들을 유추하기 귀찮았기(…😮💨😮💨) 때문이다. 다음 내용은 우리 팀원들이 나 대신해서 데이터를 분석한 내용이다.
- 훈련 데이터의 특징들을 corr() 함수를 사용하여 특징들간의 연관성을 히트맵으로 나타내었다.
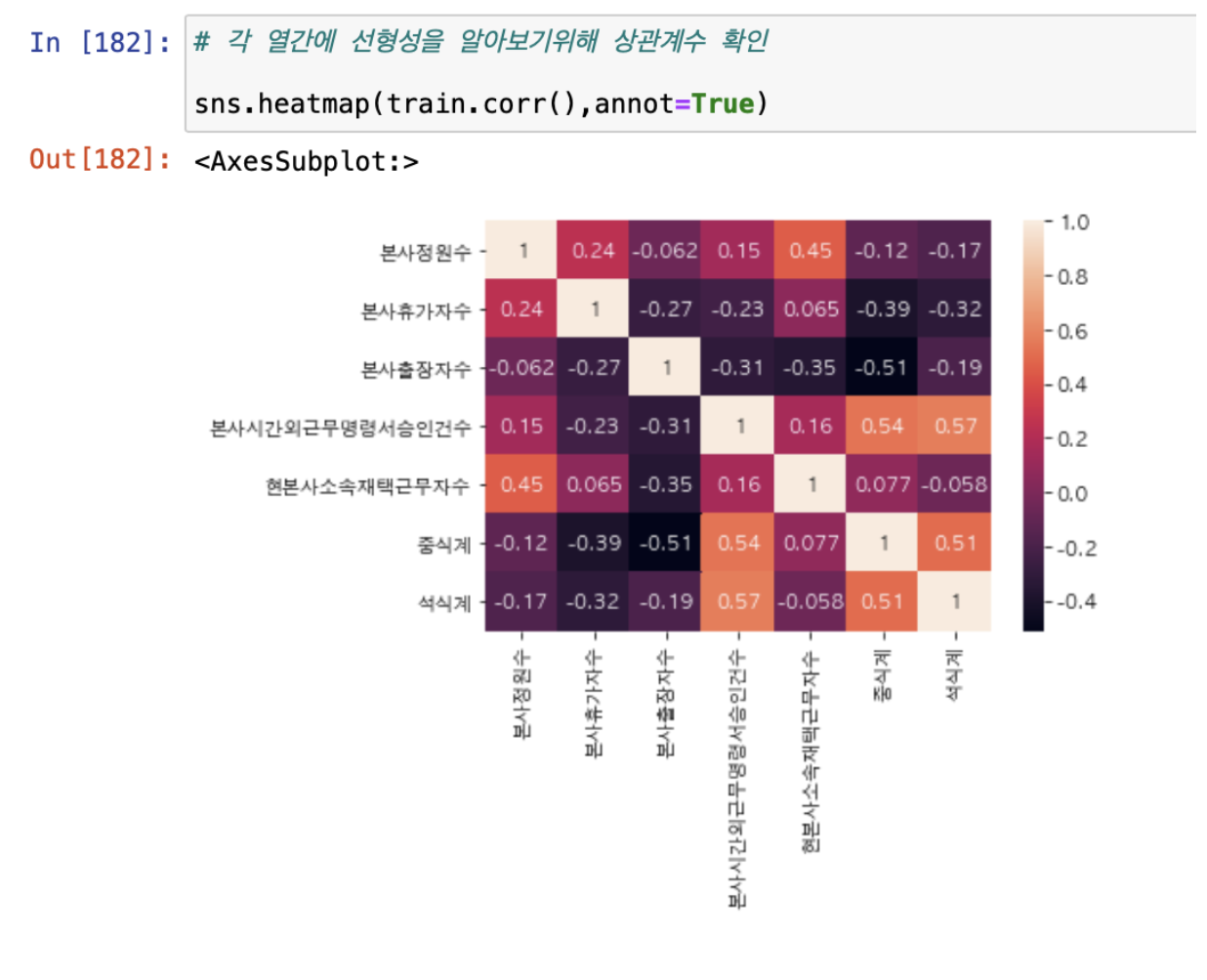
히트맵으로부터 중식계와 석식계에서 본사외근무명령승인건수와 비례하는경향을 보인것을 확인할 수 있었다.
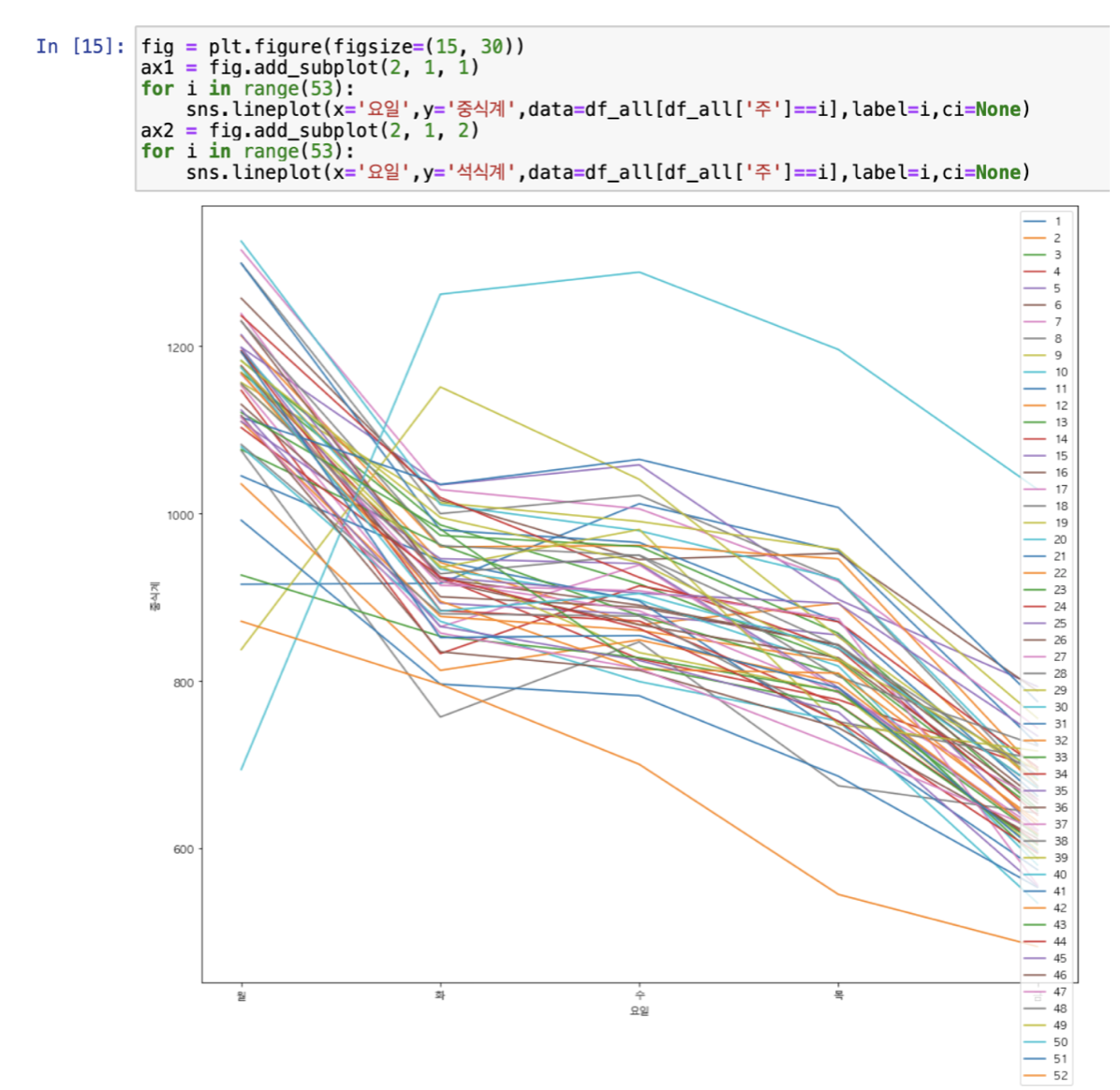
2. 요일별 평균 중식계 식수 인원을 확인하였다.
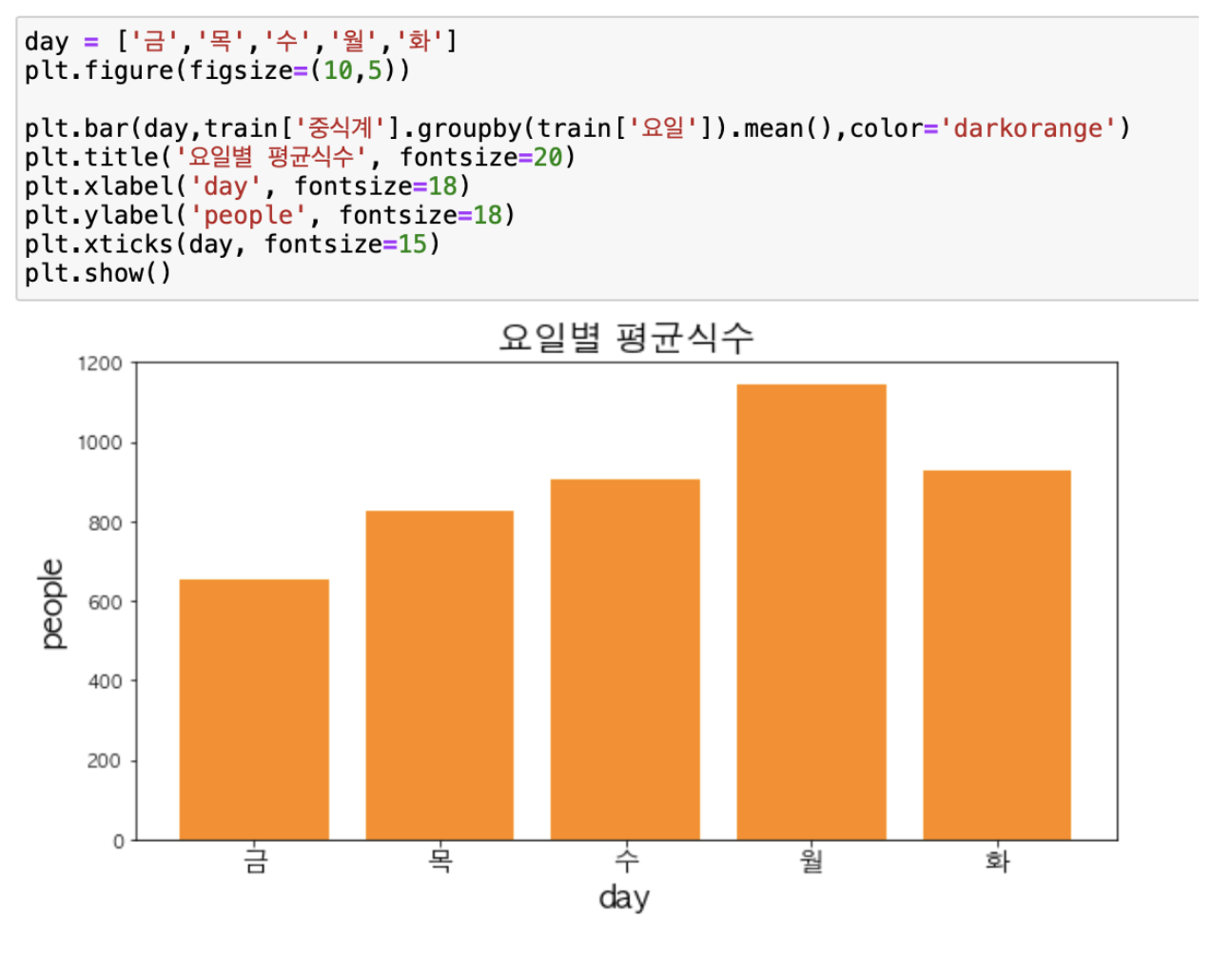
월>화=수>목>금 순으로 많은 것을 확인할 수 있었다.
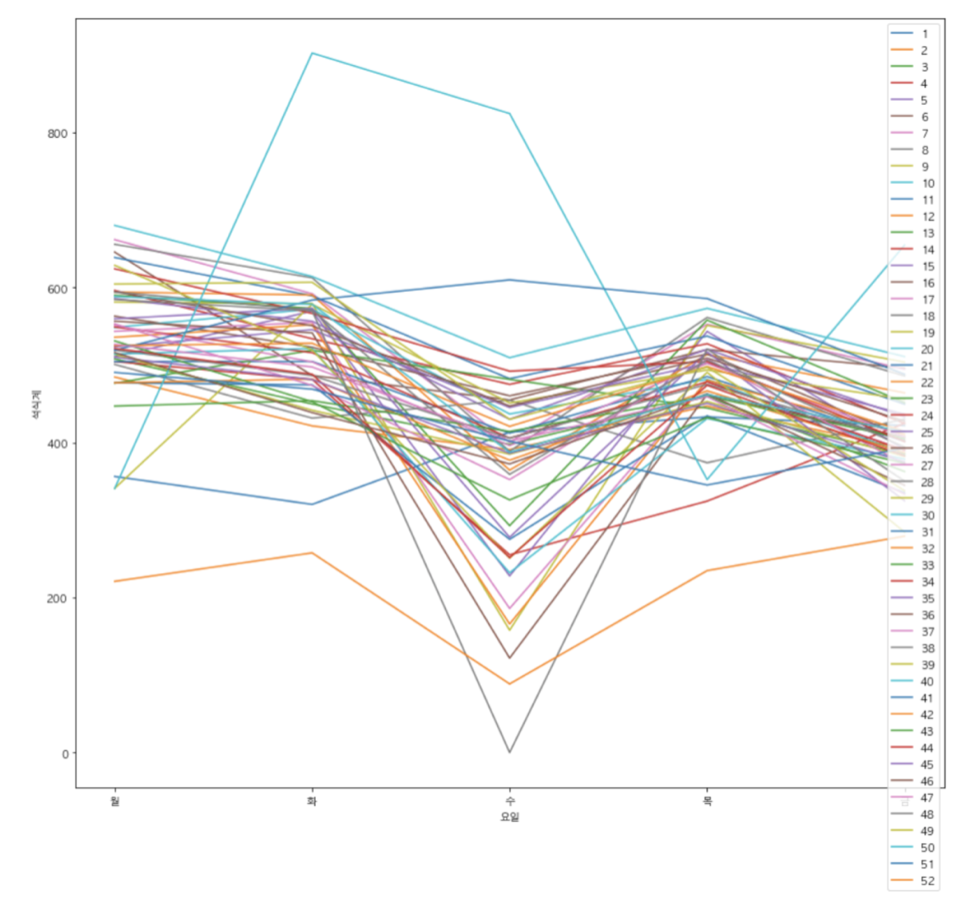
3. 마찬가지로 요일별 석식계 식수 인원을 확인하였다.
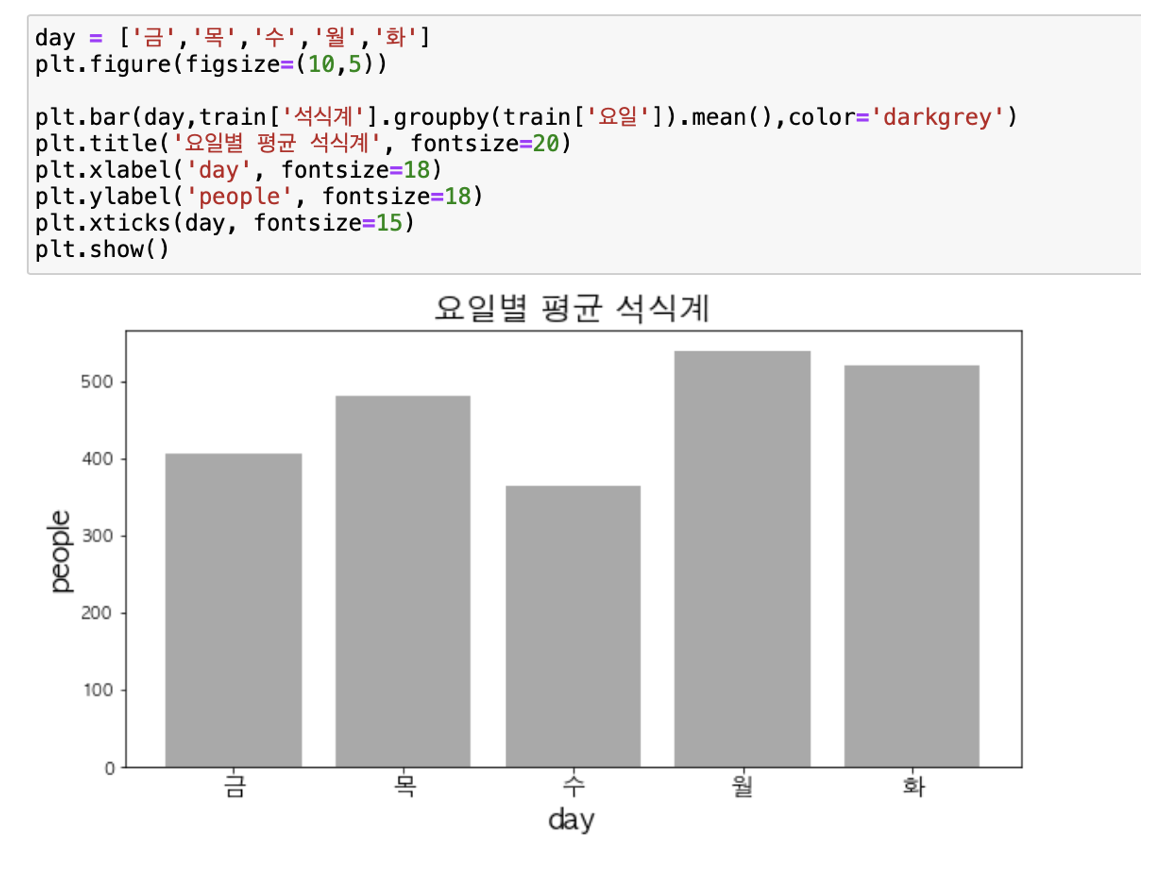
월>화>목>금>수 순으로 많은 것을 확인할 수 있었다. 수요일이 왜 가장 적은지에 대한 이유를 찾은 결과 매달 마지막째 주에 있는 문화의 날 때문에 석식계가 0이 나타나는 것 때문이라는 것을 확인했다.
4. 주, 요일별 평균 중식계, 석식계를 확인한 결과 상당히 일치 하는 것을 보아서 관련 특성을 하나 생성하기로 하였다.
-
중식계
-
석식계
5. 그 밖에 여러 분석을 시도해봤으나 마땅히 건질만한 것이 없었다.
데이터 전처리
데이터 전처리의 화두가 되는 부분은 단연 조식, 중식, 석식메뉴를 어떻게 처리할지였다. 해당 특징들은 데이터가 상당히 불친절하게 정리되어 있어 어떠한 기준으로 처리해야 될지 고민을 많이 했다. 다음은 원 핫 인코딩 방법으로 메뉴를 처리한 코드이다.
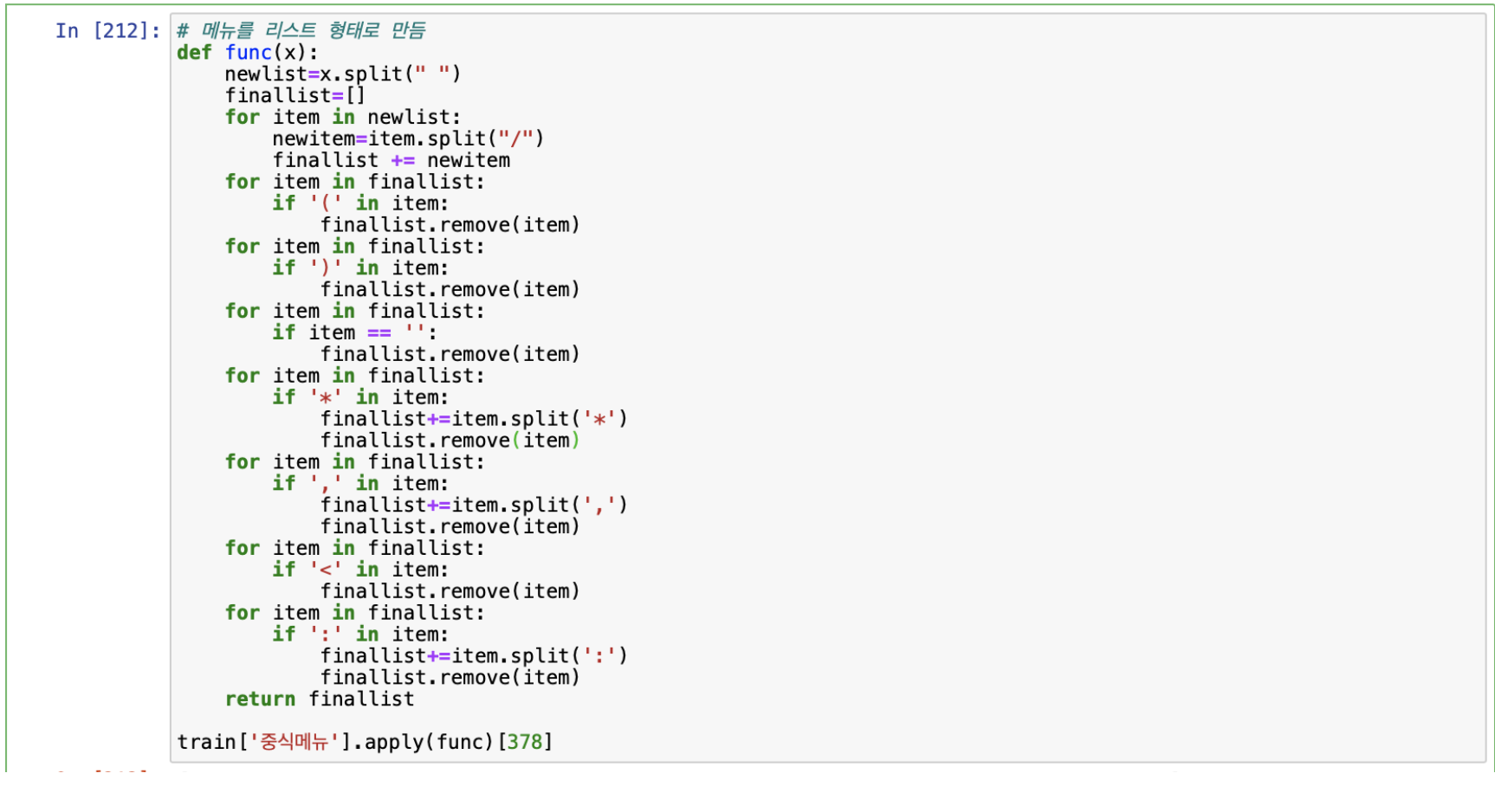
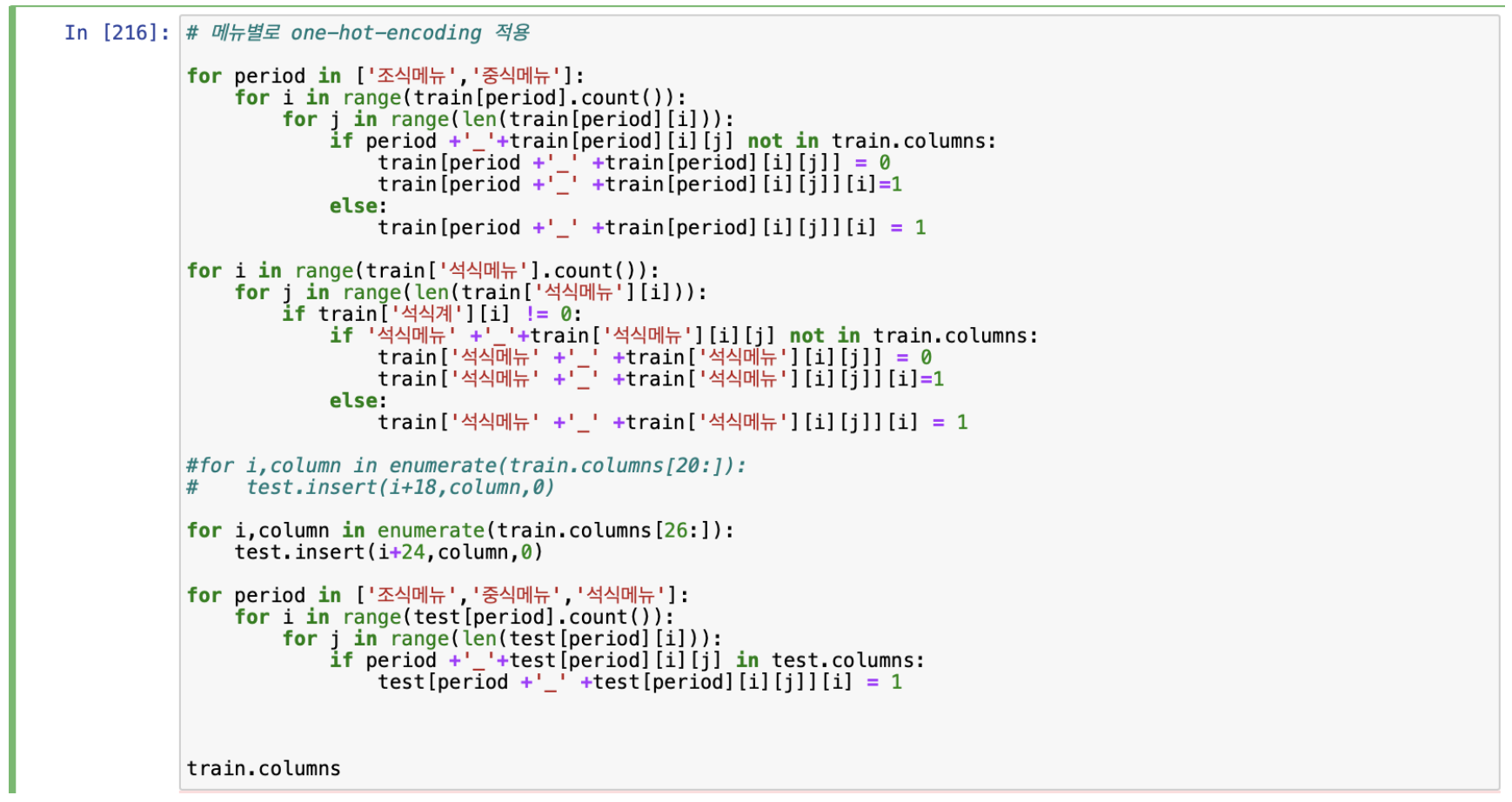
해당 코드를 실행하면 석식메뉴에 있는 어묵국은 ‘석식메뉴_어묵국’ 이런식으로 특징이 만들어지고 석식메뉴에 어묵국이 있으면 1, 없으면 0이 입력되게 된다. 그러나 이렇게 특징을 만들게 되면 4000개 가량의 특징이 생성되어 후에 모델링 작업을 할 때 소요시간이 너무 길어진다는 단점이 있었다.
그 밖의 데이터 전처리한 내용은 다음과 같다.
- 데이터 분석한 내용을 바탕으로 다음과 같은 특징들을 생성하였다.

2. 일자를 to_datetime 함수를 사용하여 년, 월, 일, 주, 요일숫자 특징으로 분리하였다.

3. 문화의날 열을 추가하였다. 석식계가 0이 되는 행의 문화의날 열의 값은 1, 석식계가 0이 아니면 문화의날 열의 값은 0이 들어가게 된다.

4. 휴일이 다음날에 있으면 식수인원이 줄어들것이라는 추측을 하여 ‘휴일전날’ 열을 넣어 휴일이 다음날에 있으면 1, 없으면 0이 들어가는 코드를 작성하였다. 공공데이터 포털의 OpenAPI를 이용하였고, 해당 코드는 모두 내가 작성한것이 아니며, 코드의 출처는 사진 아래에 첨부하였다.
5. 마지막으로 필요없다고 판단되는 특징은 삭제하였다.

모델 생성
모델을 생성하기에 앞서 중식계, 석식계 각각에 맞는 모델을 만들기 위해 데이터를 석식계만 제외된 데이터, 중식계만 제외된 데이터로 분리하였다.

책에서 배운대로 GBDT, 선형회귀, 딥러닝 순으로 모델을 생성해 보았다. 다음은 각 모델을 생성하는 코드와 검증 데이터로 평가를 했을 때 나온 점수이다.
- GBDT에는 크게 두가지 라이브러리가 사용되는데, xgboost 와 lightgbm 이다. lightgbm 이 튜닝할 매개변수도 적고 처리속도도 빠르다고 하여서 중식계 데이터에 먼저 적용해 보았다.

k-교차검증을 이용하여 5개의 폴드를 만들어 4개의 폴드로 모델을 만들고 나머지 1개의 폴드로 검증하는 방법으로 검증점수를 확인한 결과 0.8 정도가 나온것을 확인할 수 있었다. 마찬가지로 석식계 데이터에 같은 방법을 적용한 결과 0.65라는 다소 낮은 점수 결과가 나왔다.
다음으로 xgboost를 이용해 모델을 생성해 보았다. xgboost는 매개변수에 따라 성능이 천차만별로 달라지므로 최적의 매개변수를 찾는 과정을 먼저 수행하였다.

다음 코드는 위 코드 실행결과 나온 최적의 매개변수를 그대로 모델에 적용한 것이다.
같은 방법을 석식계 데이터에도 그대로 적용하였다.
2. 선형회귀 모델로 라소회귀 모델을 사용하였다. 다음은 중식계 데이터를 이용해 라소회귀 모델을 생성하고 검증 데이터에 대한 점수를 출력하는 코드이다.
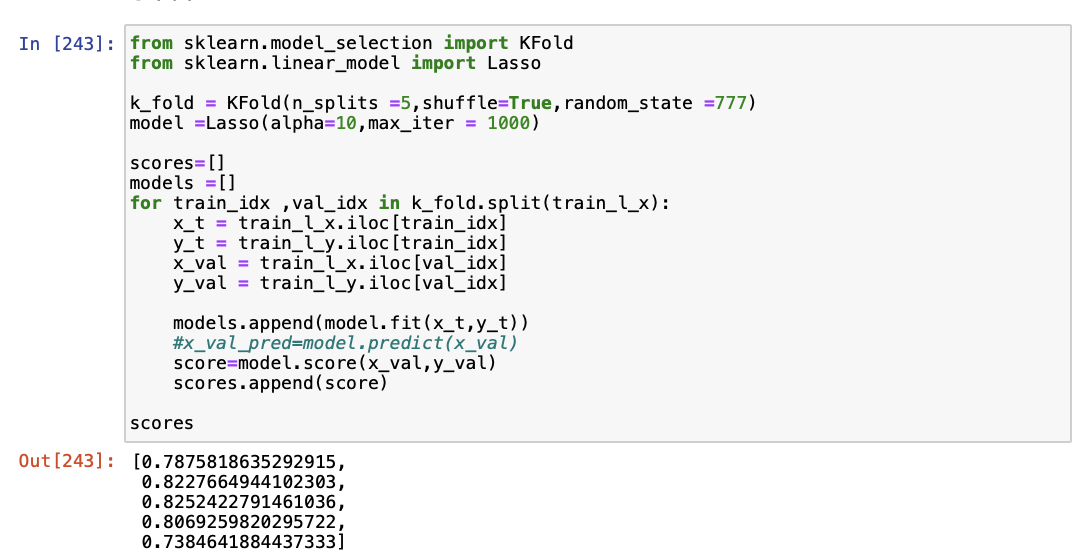
검증 데이터에 대한 점수가 0.8정도로 앞선 lightgbm 과 상당히 유사한 결과가 나온것을 확인하였다. 석식 데이터에도 같은 방법을 적용한 결과 0.63 정도의 점수가 나왔다.
3. 신경망은 사실 많이 시도해보지는 않았다. 신경망을 이용한 모델을 만들기 위해서는 keras 나 tensorflow 같은 다소 복잡한 라이브러리를 사용해야 하고 매개변수와 층을 설정하는 부분이 상당히 까다롭기 때문에 한번 시도해본다는 것에 의의를 두기로 하였다.
먼저 k-fold 분할을 이용해 데이터를 훈련, 검증 데이터로 나누었다.

신경망 모델을 만들기 위해서는 데이터 표준화가 필수적이므로 StandardScaler() 함수를 사용하여 데이터 표준화를 실시하였다.

다음으로 신경망의 input layer, hidden layer, output layer 을 설정하주는 작업을 실시하였다. hidden layer의 수는 3개로 설정하고 필요없는 특징을 삭제하기 위해 dropout 함수를 사용하였다.

다음으로 모델을 컴파일 해주고 batch_size와 epochs 수를 설정하였다.

검증 데이터를 통해 예측값과 실제값의 MAE 를 이용한 비교 결과 843 이라는 매우 높고 부정확한(…) 결과가 나온 것을 확인하였다. 또한 이 모델을 그대로 테스트 데이터에 적용하였는데 상식적으로 받아들일 수 없는 값이 나와 신경망에 대해서는 더 생각해볼 필요가 있다고 느꼈다.

public score 및 결과 분석
- lightgbm 을 이용했을 때 public score 은 91.75 정도가 나왔다.

2. xgboost 를 이용했을 때 public score 은 84.50 정도가 나왔다.

3. 선형회귀를 이용했을 때 public score 은 84.50 정도가 나왔다.

4. 신경망을 이용했을 때는 예상했듯이 처참한 점수인 405.90(…😮💨😮💨)가 나왔다.

위 결과를 통해 xgboost 가 제일 성능이 높을 것을 확인할 수 있었다. 아마 최적의 매개변수 튜닝에 따른 결과가 아닌지 싶다. 이것이 내가 얻었던 가장 좋은 결과였고, 다른 멤버는 조식, 점심, 저녁 메뉴를 삭제하고 일부 특징을 약간씩 수정한 결과 가장 좋은 점수인 81.33 을 얻었다. 사실 여기서 모델의 성능을 향상 시키기 위해 무엇을 더 해야할지 확신이 서지 않았고, 데이터 전처리 부분을 계속 반복하며 public score 을 향상시키기 위해 노력했으나 81.33 아래로 도저히 내려가지가 않아 해당 모델을 그대로 제출하였다.
1등 팀의 모델의 분석과 이번 대회를 하면서 느꼈던 점은 다음 장에서 서술하도록 하겠다
Comments