
데이콘 경진대회 참여후기 part2
경진대회에서 1등이 사용한 코드를 보려고 했는데 아쉽게 1등한 팀이 코드를 공유하지 않아 3등 팀의 코드를 참고하였다.
3등 팀의 코드를 보고 눈에 띈 점
- seaborn의 kdeplot 함수를 통해 목적변수의 분포를 그래프로 나타내었다. 해당 그래프를 통해 정규화를 해야할지 말아야 할지 여부를 판단할 수 있다. 이번 경진대회의 중식계와 석식계 특징은 이미 정규분포의 형태를 띄고 있으므로 Min-Max-scale 같은 정규화를 실시하지 않았다.

- 월별 점심과 저녁때 사람수를 boxplot을 이용해 그래프로 나타내었다. 이를 통해 연말에 식수 인원이 제일 적다는 것을 파악하였다.

- 음식 메뉴를 처리하는 과정에서 밥, 국, 반찬의 세 개의 특징을 만들어 각 특징에 해당하는 메뉴를 분리했다. 그리고 레이블인코딩을 통해 각 메뉴를 숫자로 변경하였다. 나도 LabelEncoder 라이브러리를 이용하여 레이블인코딩을 시도해 보았지만 3등 팀은 다른 방법을 통해 레이블인코딩을 하였다.
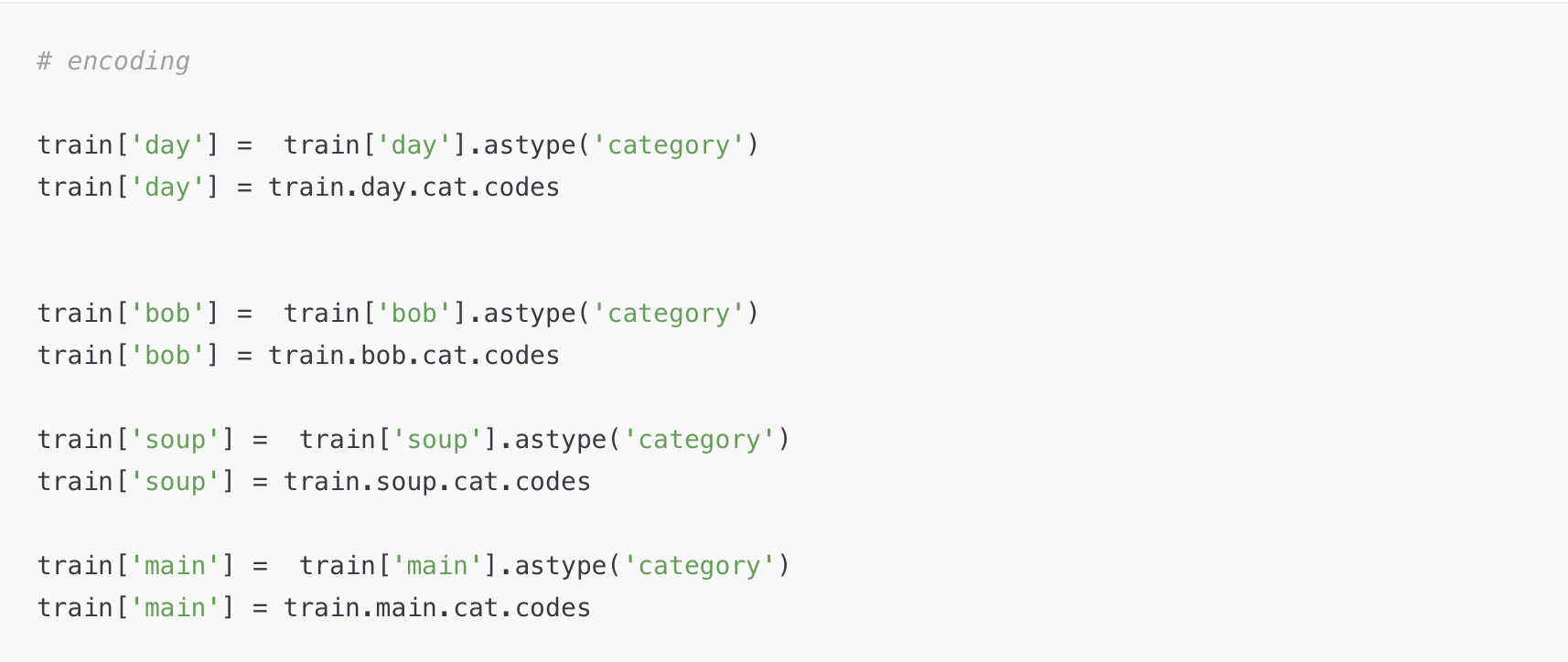
-
음식 메뉴를 분리하는 과정에서 3개의 반찬 중에서 1개만 특징에 포함시켰다. 3개의 반찬 중 메인 반찬이라고 보이는 반찬은 딱히 보이지 않는데 특징의 수를 조금이라도 줄이기 위해 1개만 포함시킨 것일까?
-
점심에 구내식당을 이용한 사람이 저녁에도 그대로 이용할 확률이 높을 것이라는 가정을 하였다. 이를 확인하기 위해 석식계를 예측할 때 다음과 같은 두가지 방법으로 나누어서 예측을 하였다.
- 석식메뉴는 제외하고 점심메뉴로만 석식계를 예측하였다.

2. 석식메뉴로 석식계를 예측하였다.

위 두 가지 경우의 public score 중 1번이 더 높게 나와 점심에 구내식당을 이용한 사람이 저녁에도 그대로 이용할 확률이 높을 것이라는 가정이 맞다는 것을 확인할 수 있었다.
- 모델은 xgboost 를 이용하였다. 다만 최적의 파라미터를 찾을 때 나는 베이즈 최적화 방법을 이용한 반면 3등 팀은 그리드 서치 방법을 이용하였다. 그리드 서치를 위해 GridSearchCV 라이브러리를 이용하였다.

3등 팀의 코드를 보며 느낀 점
- 데이터의 특징은 최대하게 간단하게 생성하였다. 나는 특징 수는 별로 생각하지 않고 학습에 도움이 될 것 같은 특징은 마구잡이로 추가했는데 이러한 특징들이 학습에 악영향을 미친 것 같다. feature_importance 와 corr 함수를 더 적극적으로 사용하여 중요한 특징들과 특징들간의 상관성을 파악을 하는 것이 중요하다.
- 데이터 분석을 다양한 방법으로 실행하였다. 데이터 분석의 중요성을 이 대회를 통해 느낀만큼 데이터 분석을 위한 라이브러리들을 많이 공부해야겠다.
- 문제에 대해 지나치게 어렵게 접근하면 진짜 중요한 것들이 보이지 않을 수 있으므로 간단하게 접근하는 태도가 필요하다.
처음으로 데이터 경진대회에 참여하여 private score 100등으로 마무리 하였지만 직접 배운 것들을 활용하고 코드를 작성하는 과정에서 많은 것들을 배워갈 수 있었다. 이 경진대회가 데이터 분석과 친해지기 위한 중요한 한 걸음이 되었으면 좋겠다😀😀
Comments