
서울시 빅데이터캠퍼스 공모전
2021년 9월 13일부터 10월 21일까지 진행한 서울시 빅데이터캠퍼스 공모전에 참가하였다. 공모전이 끝난지는 무려 한달(…)이 지났지만 후기 작성을 미루다가 지금에서야 후기를 작성하려 한다.
주제 정하기
서울시 빅데이터캠퍼스 공모전은 주제가 정해진 것이 없어 자유롭게 주제를 선정하고 선정한 주제를 바탕으로 데이터 분석을 해야한다. 주제를 선정하는 것이 상당히 힘들었는데, 3주동안 매주 한번씩 줌 회의를 하여 자료조사를 하며 어떠한 주제가 제일 적합할까 고민을 많이 하였다. 후보 주제로 다음과 같이 5개가 나왔다.
- 강남구의 청소년 쉼터의 최적의 이전 장소
- 숙박시설의 장애인 객실 설치 우선순위 정하기
- 디지털 격차 해소를위한 교육 장소 선정하기
- 복지 사각지대 파악하기
- 소비패턴을 파악하여 코로나19로 경제적인 피해를 입은 이들에게 적절한 구호물품 선정하기
내 현재 전공이 공간정보공학과이고 공간 데이터를 다루는 데는 자신이 있었기 때문에 최적의 위치를 선정하는 1~4번의 주제가 적합해 보였다. 그러나 작년에 입상을 한 팀의 주제들이 거의 다 최적의 입지를 선정하는 것과 관련이 있었고 이러한 주제는 다소 식상하다고 느껴져 입지 선정과는 무관한 5번 주제를 하기로 결정하였다. 5번 주제에서 특정 카테고리별로 구호물품을 선정할 필요가 있다고 생각하여 지역을 기준으로 삼기로 했다.
데이터 시각화
서울시 소득수준 시각화
특정지역의 전반적인 소비패턴은 그 지역의 소득수준과 연관되어 있으므로 구별 소득수준을 지도에 시각화하였다. 사용한 데이터로는 서울시 행정구 경계 데이터, 법정동별 소득수준 데이터 가 있다. 이때 경계 데이터는 행정구, 소득수준은 법정동이 기준이 되고 있으므로 QGIS 쿼리 기능의 공간 연산을 통해 행정구별 소득수준을 구했다. 다음은 공간 연산을 통한 시각화 결과이다.
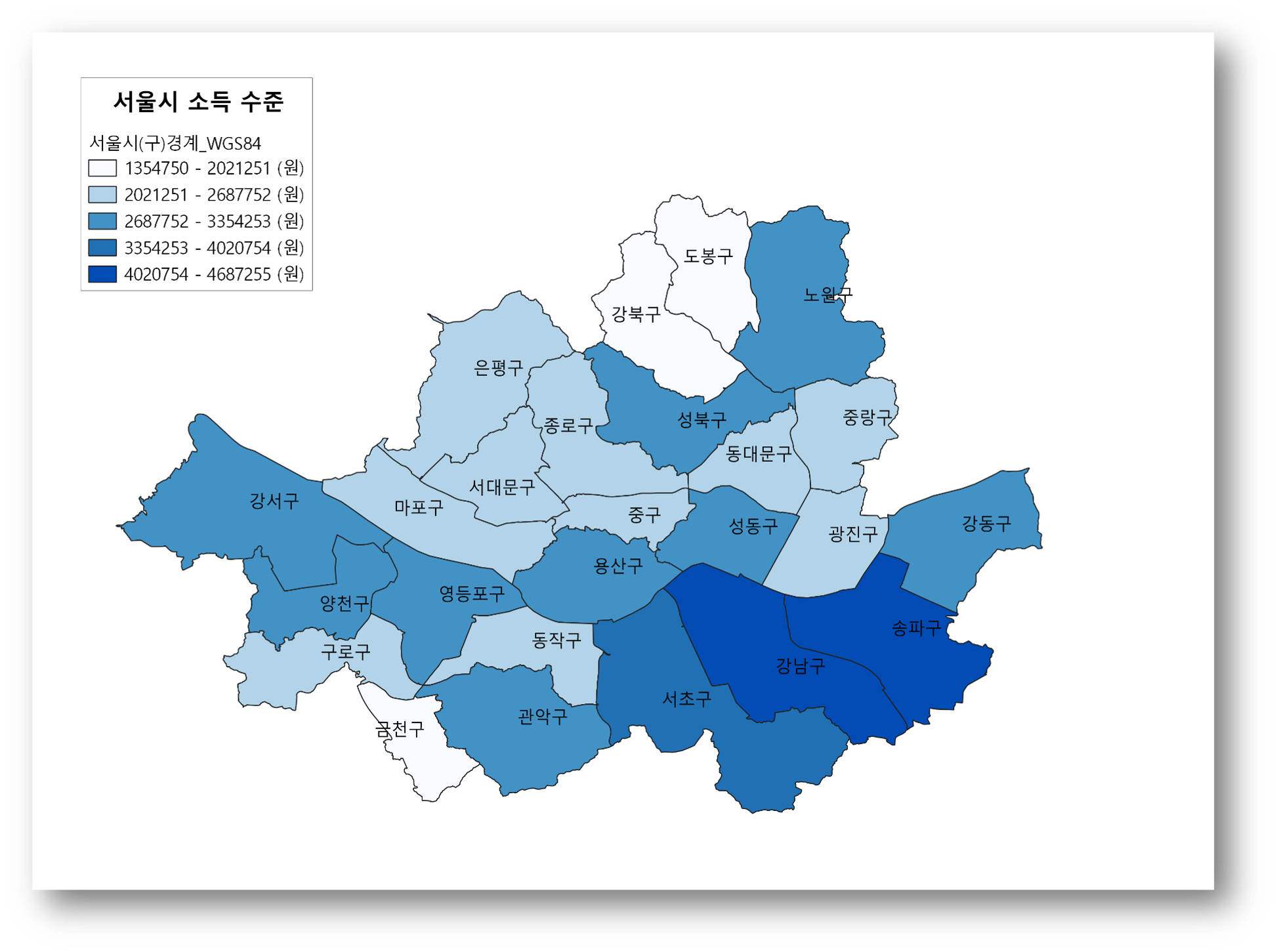
분석 결과 다음과 같은 인사이트를 도출할 수 있었다.
- 강북구, 도봉구, 금천구가 다른 구들에 비해 낮은 소득수준을 보인다.
- 송파구, 강남구가 다른 구들에 비해 높은 소득수준을 보여주고 있다.
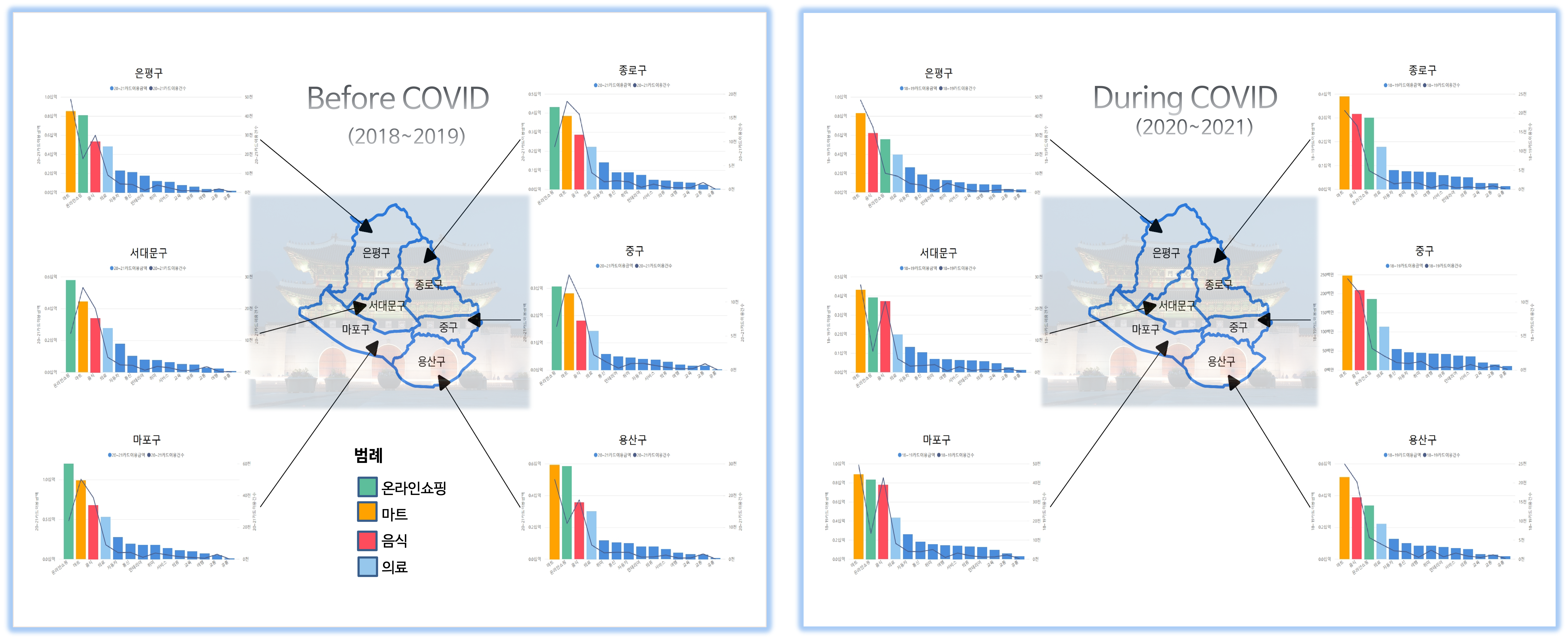
서울시 구별 코로나 전과 코로나 시기의 소비 비교
코로나 전과 후의 소비패턴의 변화를 파악해야 했기 때문에 카드소비 패턴 데이터를 구와 업종별로 sort하여 가장 큰 변화폭을 업종을 찾았다. 이를 PowerBI를 통해 그래프로 시각화하고 QGIS를 통해 시각화한 서울시 자치구 경계 데이터를 합쳐서 구별 소비패턴의 변화를 시각화 하였다.
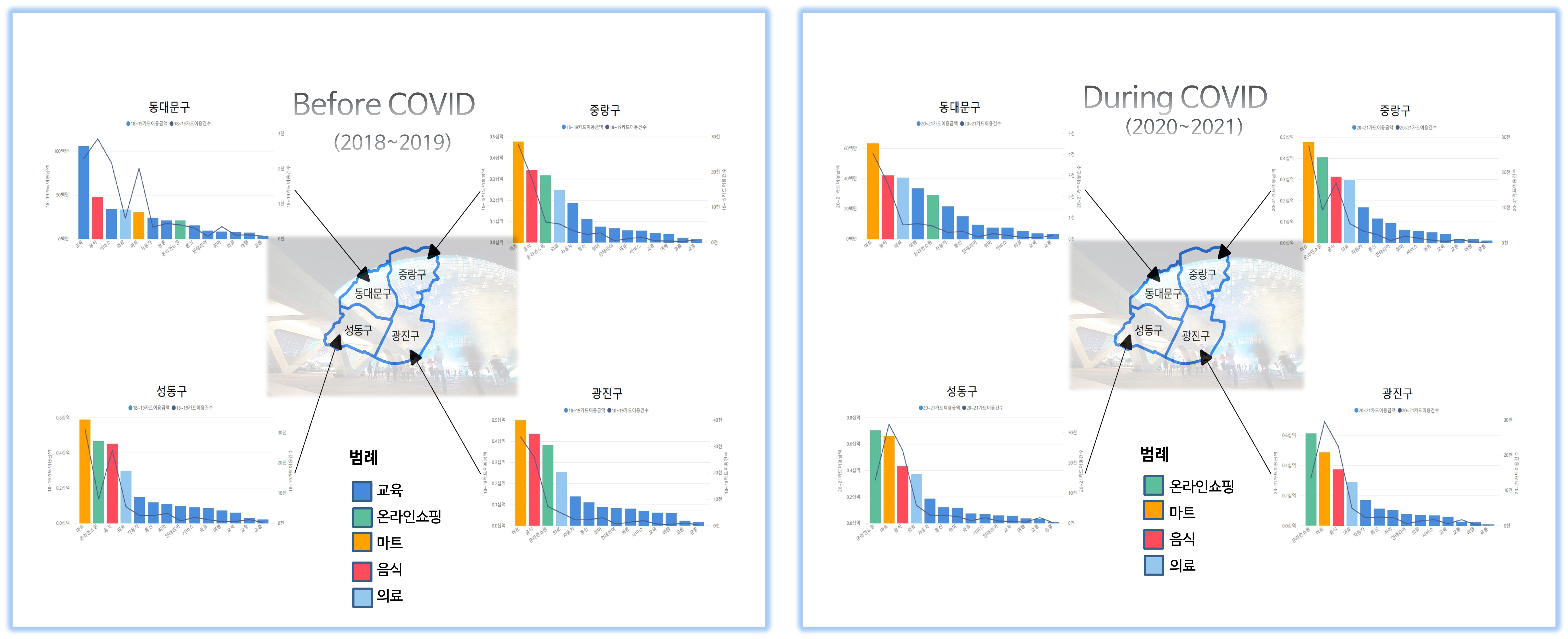
위 그래프에서 알 수 있듯이 코로나 전에는 마트, 음식, 온라인쇼핑, 교육이 상위권을 차지했으나 코로나 시기에는 온라인쇼핑이 급성장하여 가장 높은 자리를 차지하고 있는 것을 알 수 있다. 위 지도에 나타난 자치구를 제외한 다른 자치구들도 이와 비슷한 변화를 보이고 있다.
분야별 예측금액 모델링
분석 계획
자치구의 경제적, 인구적 특징이 드러나는 데이터를 독립 변수를 설정하고 미래의 각 자치구의 업종별 매출이나 소비 금액을 종속 변수로 설정하였다. 여기서 머신러닝 기법을 이용하여 자치구의 업종별 매출을 예측하는 모델을 만들어 보았다.
사용 데이터
- 서울시민의 업종별 카드소비 패턴 데이터
- 블록별로 요식업, 스포츠/문화/레저, 교육 등 73개 업종의 연월별 카드소비금액계와 카드소비건수계를 제공하고 있다. 여기서 블록을 자치구로 mapping하고 자치구별, 연월별, 업종별 데이터로 변환하여 카드소비금액계를 종속변수로 설정하였다.
- 행정동 단위 거주인구 데이터
- 행정동별로 거주인구 데이터를 제공하고 있다. 행정동 코드를 행정동-자치구 변환 데이터와 조인하여 자치구로 변환하고 자치구별, 연월별 인구 합계 데이터를 생성하여 독립변수로 사용한다.
- 서울시 상권발달 개별지수
- 행정동별로 가맹점, 매출, 인구, 금융 관련 지표를 제공하고 있다. 행정동 코드를 자치구로 변환하고 자치구별, 연월별 데이터를 생성하여 독립변수로 사용한다.
데이터 전처리
6개월간의 데이터를 이용해 다음 달의 카드소비금액계를 예측해야 했기 때문에 시계열 데이터 분석을 고려한 데이터 변환을 하였다. 아래 그림에 나타난 것과 같이 6개월 동안 나타난 독립변수들을 한번에 묶어서 한 열로 통합하였다.
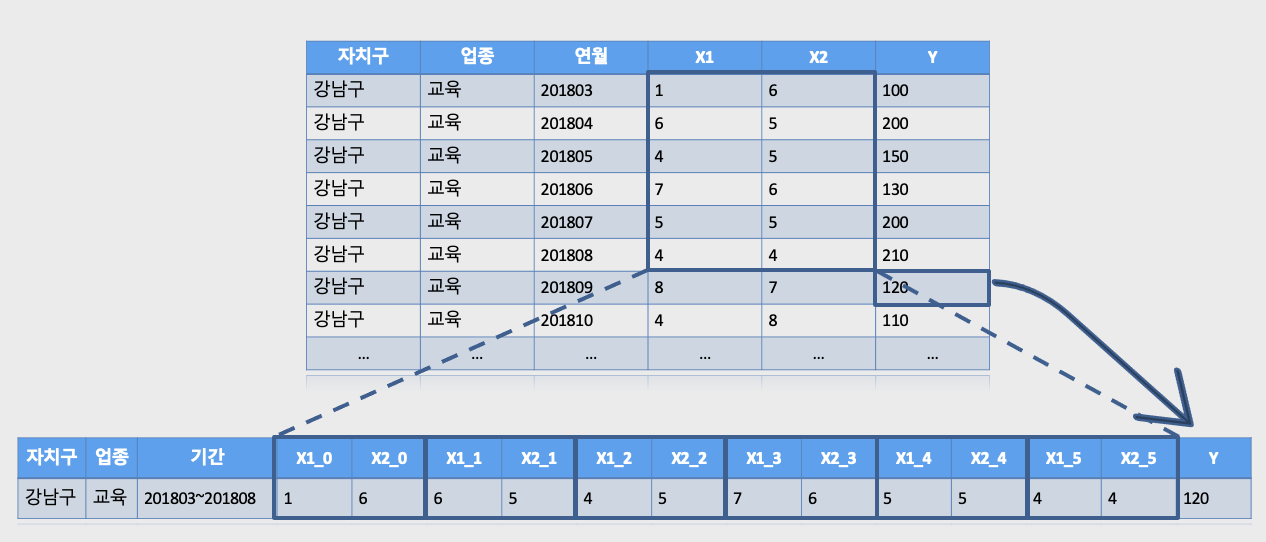
모델링 방법
여기서 보편적인 상황에서 가장 좋은 성능을 보여주는 RandomForest를 예측모델로 사용하였다. 2018년 7월부터 2020년 4월까지의 데이터를 훈련 데이터로 설정하여 6개월 단위로 훈련을 진행하였고 2020년 5월부터 9월까지의 데이터를 테스트 데이터로 설정하여 성능을 확인하였다.
분석 결과
각 자치구의 2020년 5월부터 9월까지의 데이터를 예측한 것을 시각화하였다. 다음은 좋은 결과가 나타난 업종을 실제값과 예측값을 비교하여 그래프로 시각화한 결과이다. 여기서 x축은 5월부터 날짜를 DOY(date of year)로 변환하여 나타낸 값이다.
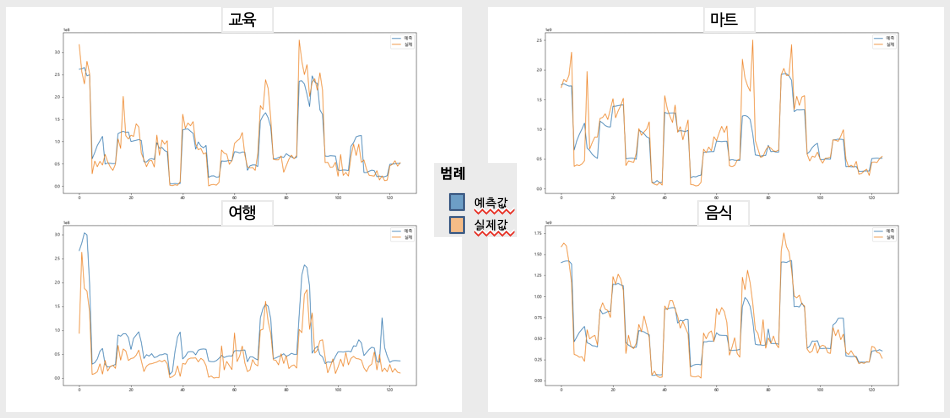
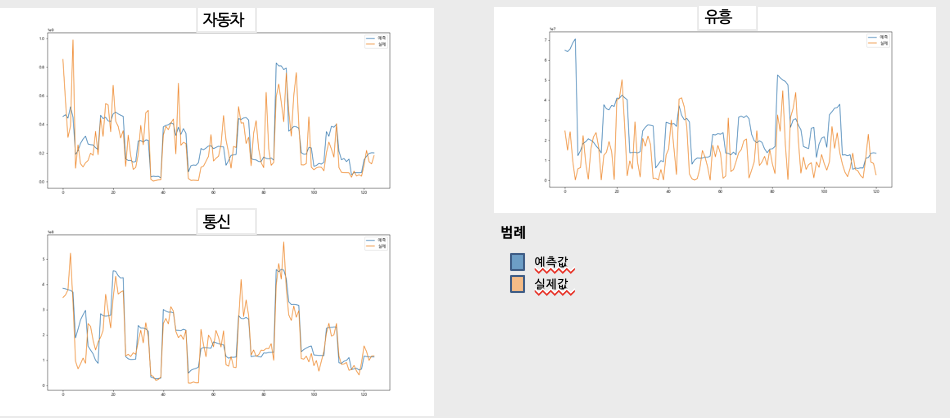
반대로 앞의 4개 업종에 비해 좋지 않은 성능을 보여주는 업종도 있었다. 데이터 부족이 원인이거나 지역구의 경제적 지표와 관련 없는 업종이기에 좋지 않은 성능을 기록했을 가능성이 있다.
온라인 쇼핑몰 분야별 예측금액 모델링
배경
앞서 데이터 시각화를 통해 코로나19로 인해 온라인 쇼핑의 매출이 급격하게 상승했다는 인사이트를 도출할 수 있었다. 따라서 온라인 쇼핑 분야만 따로 매출을 예측해야 할 필요성을 느껴 온라인 쇼핑몰의 매출금액을 분야별로 모델링 해보았다.
모델링 방법
여기서 사용한 모델로는 Prophet이 있다. Prophet은 이 공모전을 진행하면서 처음으로 접한 모델이였는데, 이 모델의 특징은 다음과 같다.
- 페이스북에서 만든 시계열 예측 라이브러리이다.
- Prophet은 시계열 데이터 예측에 최적화된 모델로, 트렌드, 계절성, 공휴일을 자동으로 반영하여 이를 고려하여 손쉽게 모델을 만들 수 있다.
-
다음과 같은 공식을 가지고 있다.
$y(t)=g(t)+s(t)+h(t)+ϵi$
- g(t) : 주기적이지 않은 변화인 트렌드를 나타낸다.(부분적으로 선형 또는 logistic 곡선으로 이루어져 있다.)
- s(t) : Seasonality, weekly, yearly 등 주기적으로 나타나는 패턴들을 포함한다.
- h(t) : 휴일과 같이 불규칙한 이벤트를 나타내는 변수이다. 만약 특정 기간에 값이 비정상적으로 증가 또는, 감소했다면, holiday로 정의하여 모델에 반영한다.
사용한 데이터로는 2017년1월부터 2021년6월까지의 정보가 나타난 통계청의 온라인 쇼핑몰 데이터이다. 2017년1월부터 2021년 4월까지를 훈련 데이터로, 4월부터 6월까지의 데이터를 테스트 데이터로 설정하여 훈련을 진행하였다.
분석결과
다음은 각 업종별로 예측한 결과와 테스트 데이터의 비교, 5달 후의 매출금액을 예측한 결과이다.
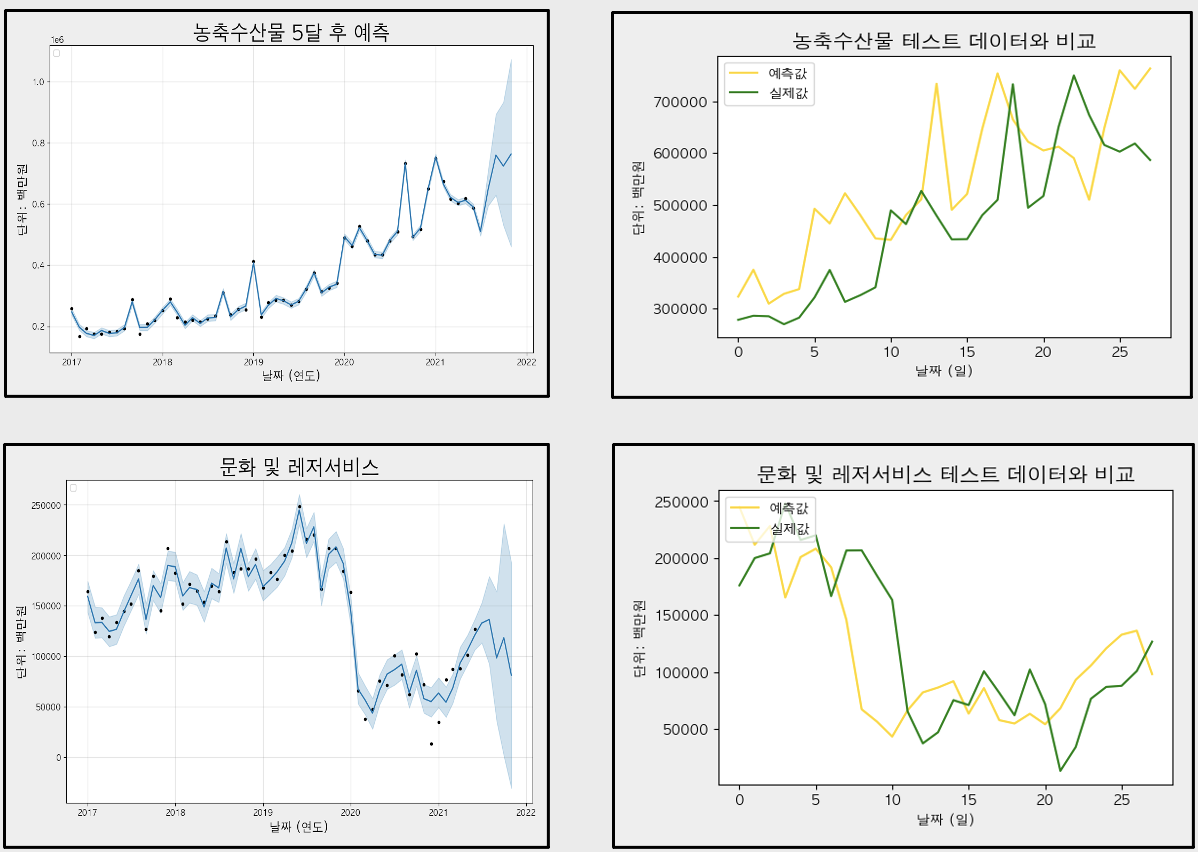
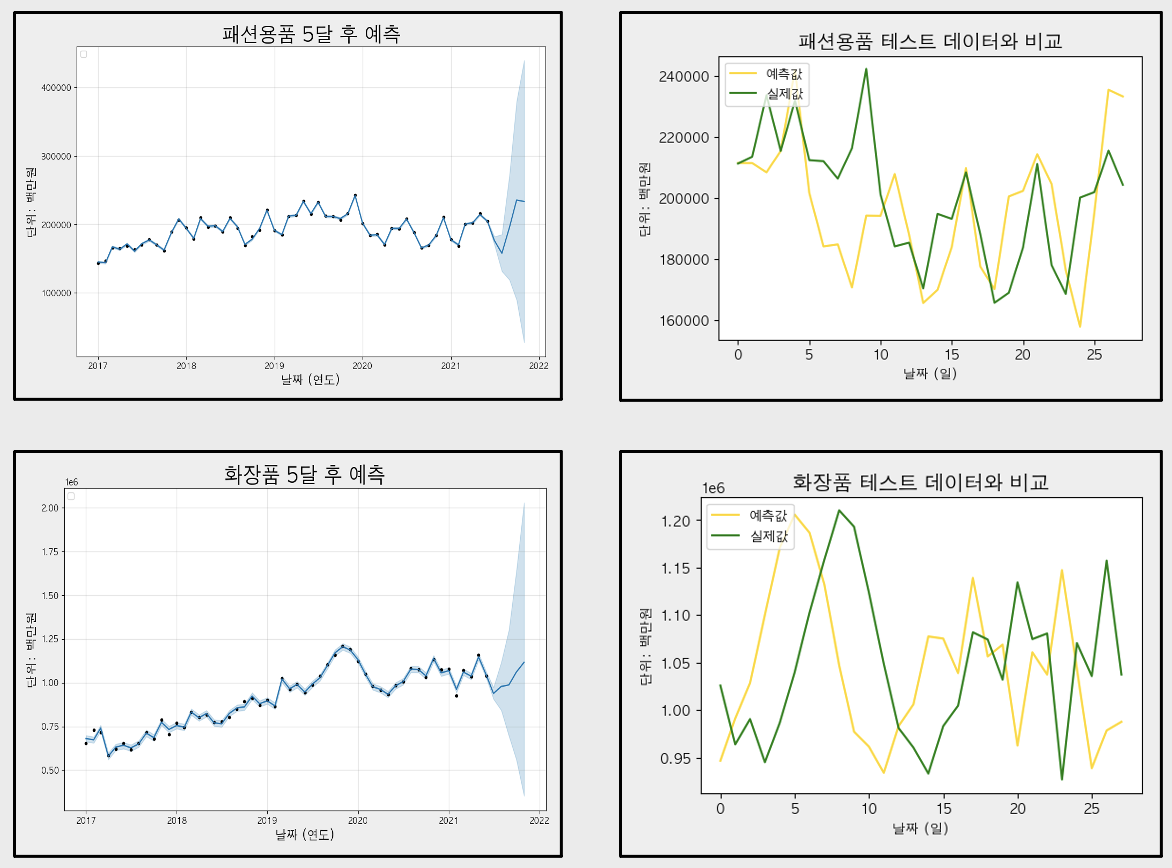
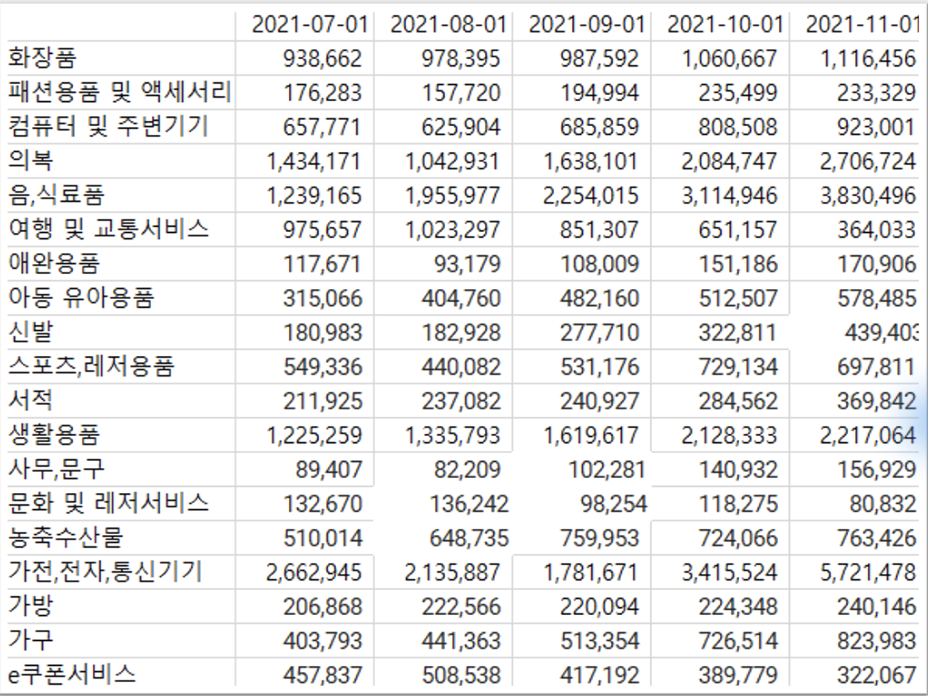
다음은 2021년 7월부터 11월까지의 매출금액을 예측한 결과이다.
결론
지금까지의 분석활동을 통해 다음과 같은 결과를 도출할 수 있었다.
- 데이터 시각화
- 데이터 시각화로 각 자치구별로 코로나 전과 후의 거래되는 품목들의 동향을 파악할 수 있었다.
- 지역구별 상권발달 개별지수와 거주 인구수를 바탕으로 카드소비금액 예측
- 2020년 5월~9월의 업종별 카드소비금액을 안정적으로 예측할 수 있었다.
- 정보가 최신화 된다면 코로나19 이후 지역별로 어떤 업종의 소비를 지원할지, 어떤 업종이 활성화될지를 예측하고 코로나19 이후를 대비하는 정부정책에 반영할 수 있을 것이다.
- 온라인 쇼핑몰 상품거래액 분석
- 2021년 11월에 가전통신기기, 음식료품, 의복의 거래액이 상위에 있음을 알 수 있었다.
- 이를 통해 온라인 문화상품권을 지원해줄 항목을 알 수 있었다.
Comments