
Masked Language Model vs Causal Language Model
BERT와 같은 Masked Language Model과 GPT와 같은 Causal Language Model의 차이점을 정리해보았다. 해당 링크를 참고하여 작성하였다.
Masked Language Model
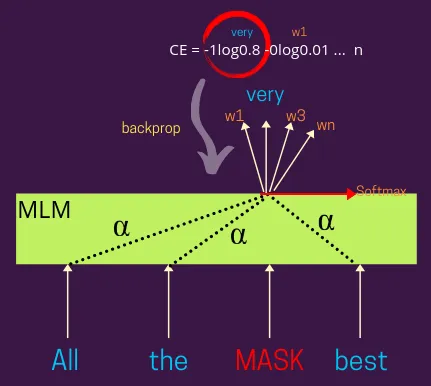
Masked Language Modeling(이하 MLM)에서는 일반적으로 주어진 문장에서 일정 비율의 단어를 가리고 모델이 그 가려진 단어를 해당 문장에서 다른 단어들을 기반으로 예측하는 것을 목표로 한다. 이러한 훈련 방식은 이 모델이 양방향적인 성격을 가지도록 만드는데, 가려진 단어의 representation은 해당 단어가 나타나는 좌우의 단어들을 기반으로 학습되기 때문이다.
여기서 가려진 단어의 표현은 BERT와 같은 attention 기반으로 될 수도 있고 그렇지 않을 수도 있다. Alpha(어텐션 가중치)의 분포에 기반하여 가려진 단어의 표현을 학습하기 위해 다른 입력 단어의 표현을 가중치를 두어 조절할 수 있다. 예를 들어, Alpha=1은 주변 단어들에 동일한 가중치를 부여하여 (즉, 모든 단어가 MASK 표현에 동일한 기여를 한다는 뜻으로) 학습할 수 있다.
아래 그림은 MLM에서 역전파가 일어나는 과정을 나타낸 것이다.
Causal Language Model 설명
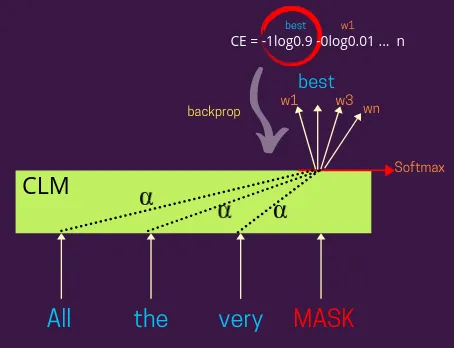
MLM에서는 주어진 문장에서 가려진 토큰을 예측하기 위해 양뱡향을 모두 고려하지만, Causal Language Model(이하 CLM)은 좌측에 나타난 단어들만을 고려할 수 있다. 이때, 단방향만을 고려할 수 있도록 하기 위해 Masked Attention을 사용하며,
CLM은 주어진 문장에서 나타난 좌측 단어들을 기반으로 가려진 토큰을 예측해야 한다. 모델이 실제 레이블에 대한 예측에 따라 교차 엔트로피 손실을 계산하고 이를 다시 모델 파라미터를 훈련하는 데에 역전파한다.
여기서도 가려진 단어의 representation은 GPT와 같은 attention 기반으로 될 수도 있고 LSTM과 같이 어텐션 없이 설계될 수도 있다. Alpha의 분포에 기반하여 가려진 단어의 표현을 학습하기 위해 다른 입력 단어의 표현을 가중치를 두어 조절할 수 있다. 예를 들어, Alpha=1은 주변 단어들에 동일한 가중치를 부여하여 (즉, 모든 단어가 MASK 표현에 동일한 기여를 한다는 뜻으로) 학습할 수 있다.
이러한 시스템들은 또한 Decoder-only 모델이라고도 불린다. 왜냐하면 기계 번역, 텍스트 요약 등과 같은 전형적인 Encoder-Decoder 아키텍처에서의 decoder와 유사하게 작동하기 때문이다.
아래 그림은 CLM에서 역전파가 일어나는 과정을 나타낸 것이다.
어떤 경우에 어떤 방법을 사용하는 것이 좋을까?
MLM은 입력 문서의 embedding을 학습하는 데에 유용하다. 해당 단어의 좌우에 나타난 단어들을 알아야 그 단어가 정말로 가지고 있는 의미를 알 수 있기 떄문이다. 반면, CLM은 주로 텍스트를 생성하는 시스템을 학습하고자 할 때 선호된다. 인간이 실제로 글을 쓸 때 이전까지의 작성한 글을 통해 다음 글을 작성하는 것과 비슷한 원리이다.
Comments