
제4회 AI x Bookathon 참여후기
지난 3주(22.12.27~ 23.1.18) 동안 진행되었던 AI x Bookathon 대회에 대한 후기를 남기고자 한다. 해당 대회는 Language Model을 이용해 수필을 작성하는 해커톤 대회로, 예선과 본선으로 이루어져 있었다. 예선은 딥러닝의 기초 지식들에 대한 퀴즈를 푸는 형식으로 진행되었고 문제 난이도는 생각보다 어려워 풀면서 적잖이 당황했던 기억이 난다. 그렇게 예선을 통과하고 무박 2일로 진행하는 본선에 진출하게 되었는데, 본선에 대한 자세한 내용은 다음과 같은 순서로 진행하도록 하겠다.
- 데이터 크롤링
- 데이터 전처리
- 모델 훈련
- 본선
- 후기
데이터 크롤링
우리는 데이터를 다음 사이트들로부터 크롤링을 하였다.
- 글틴
- 브런치
- 대표 에세이 문학회
- 동아신축문예
- 모두의 말뭉치
우리는 최대한 많은 수필 데이터를 수집한 후 Language Model에 학습할 계획을 세웠기 때문에 각 사이트 별로 약 10MB에 해당되는 데이터를 크롤링 하였다.
데이터 전처리
우리는 KLUE: Korean Language Understanding Evaluation 논문에서 사용된 전처리 방법을 참고 하였다. 해당 논문은 다음과 같은 방법을 이용하였다.
1. Noise Filtering: 의미 없이 나열되는 공백과 문자(hashtag, HTML tag, copyright tag등)들을 제거하였다. 2. Toxic Content Removal: 성 차별적인 문장이나 혐오 표현들이 포함된 문장을 삭제하였다. 3. PII Removal: 개인정보와 관련된 문장, 즉 @gildong 와 같은 이메일, 다른 유저를 멘션하는 키워드, 웹페이지 주소를 삭제하였다.
모델 훈련
우리는 사용할 모델과 모델 훈련 전략을 다음과 같이 세웠다.
1. GPT3 기반 모델 사용하기
가장 최신 language model인 GPT3를 사용하는 것이 가장 좋은 성능을 보일 것이라고 생각해 처음에는 kakaobrain에서 제공한 koGPT를 사용하였다. 적용한 결과 우리가 사용한 GPU의 성능이 좋지 않아 GPU 메모리 부족현상이 나타났지만 Gradient Accumulation 방법을 사용하여 해결하였다. 그러나 해당 방법을 적용하였을 때 훈련하는 시간이 너무 오래 소요되었기 떄문에 GPT3보다 이전에 나온 모델인 GPT2 기반 모델을 사용하기로 결정하였다.
2. GPT2 기반 모델 사용하기
우리는 Huggingface 사이트에서 여러 GPT2 모델을 발견하였다. 그 중에서 한국어 데이터셋으로 추가 학습한 SKT-KoGPT2 모델을 사용하기로 하였다. 이렇게 pretrained된 KoGPT2를 우리가 크롤링해서 수집한 데이터로 fine-tuning 시켰다.
3. 논문 참고
기본 베이스 모델인 KoGPT2에 프롬프트 문장을 넣어서 다음 문장을 생성하였더니 조금만 많이 생성해도 문장의 일관성이 유지되지 않는다는 사실을 파악했다. 따라서 우리는 문장의 일관성을 유지하는 동시에 문장을 생성하는 우리 팀 만의 novelty를 가질 수 있는 방법을 찾기 위해 논문을 찾아 보았다. 그 중 참고한 논문은 Progressive Generation of Long Text with Pretrained Language Models 으로, left-to-right fashion이 아닌 아래 그림에 나타난 방법으로 문장을 생성하게 된다.
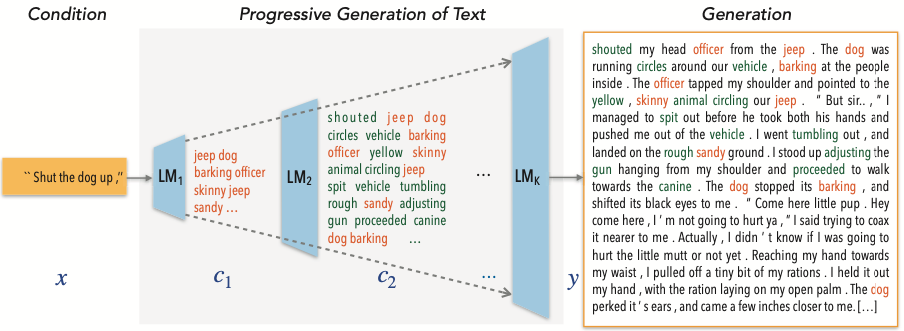
위 그림의 process를 간단하게 설명하면 다음과 같다.
- output text인 $y_t$ 는 intermediate sequence인 $c_k$ 를 conditioning 하여 생성된다.
- 여기서 $c_k$ 는 vocabulary set인 $V_k$ 으로부터 생성된 sequence 이다.
- $V_k$ 는 $k$ 가 커질수록 사이즈가 커지게 된다.
- 따라서 위 그림과 같이 처음에는 중요한 단어들(여기서 단어들의 중요도를 tf-idf로 구한다)이 먼저 생성이 되고 덜 중요한 단어들이 점차 생성되며 문단을 생성하게 된다.
해당 논문에 사용된 코드를 fork하여 koGPT2와 koBART(해당 논문에서 GPT2와 BART를 사용하였기 때문에 해당 기반 모델을 사용하였다)를 그대로 해당 코드에 적용해 보았다. 그러나 pytorch hub에서 koBART를 불러오는 과정에서 문제가 생겼고 이 문제를 해결하려고 하였지만 대회까지 남은 시간이 많이 없었기 때문에 다른 방법을 찾을 수 밖에 없었다.
4. 에피소드별 주제 선정
우리는 koGPT2를 아무리 적절하게 훈련을 시켜도 2만자 내외의 문장을 일관되게 생성해 낼 수 없을 것이라고 판단하고 인공지능 모델이 글을 처음부터 끝까지 써 내려가는 작가가 아닌 인간이 직접 플롯을 구성하고 해당 플롯 안에서 적절한 문장을 생성해 내는 보조작가의 역할을 부여하기로 하였다. 따라서 우리는 다음과 같은 방법으로 수필을 생성해내기로 하였다.
- 직접 플롯을 구성한다.
- 플롯을 여러 개의 에피소드로 나눈다.
- 에피소드별 키워드를 선정한다.
- 키워드를 브런치에 검색한 뒤 나오는 브런치 데이터들을 크롤링한다.
- 크롤링한 데이터를 koGPT2에 fine-tuning 시켜 에피소드 별로 다른 모델을 생성한다.
- 처음 에피소드의 프롬프트 문장만 직접 작성한 뒤 그 이후로 나오는 문장은 인공지능 모델에게 맡긴다.
- 문장을 n개 생성하고 그 중 마음에 드는 문장을 선택한 뒤 다음 프롬프트로 넣는다.
본선
본선에서 주어진 주제는 ‘담대함’ 이였다. 우리는 ‘담대한’을 주체성을 찾는 과정, 즉 터부시되는 경계를 깨트리고 다음 단계로 나아가는 원동력이라고 생각하였다. 이러한 속성이 모더니즘의 기조인 전통적인 기반에서 급진적으로 벗어나려는 시도와 상당히 유사하다는 발상을 하게 되었다. 여기서 우리는 모더니즘에서 더 나아가 모더니즘을 대표하는 화가인 모네를 떠올렸고 ‘주인공이 모네의 작품과 타인을 만나며 자신의 삶을 담대하게 맞서 나간다’ 라는 스토리를 구상하였다. 우리가 선정한 에피소드 별 키워드는 다음과 같다.
Episode 1) 회상, 모네
Episode 2) 평범
Episode 3) 인생의 전환점
Episode 4) 주체성, 꿈
Episode 5) 담대함, 변화
Episode 6) 이동, 회상
Episode 7) 갈등, 회상
Episode 8) 갈등, 이별, 친구
Episode 9) 현실, 순응, 공부
Episode 10) 추억, 담대
대회에 사용된 코드와 최종적으로 생성한 수필은 아래 링크에서 찾아볼 수 있다.
github
후기
처음으로 참여한 NLP관련 대회였지만 최우수상이라는 좋은 성과를 거두어서 너무 좋았다. 최종 발표 시간에 다른 팀이 발표한 내용을 통해서도 많은 것을 배울 수 있었다.
이 대회의 핵심은 ‘얼마나 인공지능이 인간의 개입은 최소화 한 채로 좋은 글을 써 내려갈 수 있느냐’ 가 아니라 ‘얼마나 인공지능이 인간을 도와 좋은 글을 작성할 수 있도록 할 수 있느냐’ 이라고 생각한다. 이러한 점은 부족한 GPU 성능 때문에 어쩔 수 없으나 수필의 결과물 보다는 수필을 만드는 과정이 좀 더 중요하게 평가되어야 하지 않냐는 개인적인 아쉬움이 든다. 언젠가는 인공지능이 인간의 개입 없이 글을 완전하게 생성하는 미래를 꿈꾸며 후기를 마치도록 하겠다.
Comments